win64和linux 使用总是报错
求教nodejs 连接nwrfcsdk方法(node-rfc)
↧
↧
听数学老师讲996能赚多少钱
油管 watch?v=U4kpHYIuV6c
↧
基于element-ui、eggjs构建权限管理系统
↧
MySQL在Debian8.6上安装的问题
请问各位大神这个是什么原因呢???感谢
↧
直播监控网站设计
直播监控网站设计,需要一页播放 n 个视频。 当前方案:使用 flv.js 作软解,性能上无法突破浏览器的限制。 正在研究方案: electron 集成 ffmpeg 开发桌面端,ffmpeg 解码,同样也有性能问题。 各位大佬支招,有啥好的方案,或者视频监控网站案例。
↧
↧
写了个导航,过来收割一波网站
↧
node v8.1.3 pm2问题
请问为什么会这样呢???之前配置的服务器是可以的
↧
【北京】BigOne Lab 被标普全球战投最酷的金融科技公司 - 招聘资深全栈工程师 35-45K
高级Web全栈开发工程师 北京·3-5年·本科 工资:35-45K
**关于我们 ** 百观科技(BigOne Lab) 是一家国际化的金融数据技术公司,致力于为全球投资机构挖掘、分析互联网时代所产生的大数据,提供可视化投资决策数据产品。百观正在打造新一代的投资研究产品,目前我们已经为二级市场机构投资者开发出监测多家上市公司运营和财务指标的数据产品,促成了大数据在金融领域的领先应用。百观于2016年获得了真格基金百万美元天使轮融资,2017年获得了华创资本数百万美元Pre A轮融资,2019年获得标普全球(S&P Global)在中国的第一笔战略投资。
我们位于北京,是一个快速成长的国际化创业团队,成员来自JP.Morgan, Bridgewater,Amazon, Bloomberg, IBM, MUFG, Yipit Data, iResearch等国际一流技术、数据、与金融公司,团队有1/3成员拥有海外学习与工作经历。团队成员毕业于清华大学、北京大学、香港大学,新加坡国立大学,哥伦比亚大学,华盛顿大学、约翰.霍普金斯大学,达特茅斯学院等海内外知名院校。
** 职位描述:** Web全栈开发工程师将是百观Lab最终产品的把控者。在自由开放的氛围下,用前沿的前后端技术,将百观Lab的数据以最佳方式呈献给给分布于世界各地的顶级投资机构。
职责:
- 带领工程师团队,负责BigOne Lab 产品开发,迭代和维护
- 带领工程师团队探索前沿的数据可视化与前后端技术
- 积极面向团队进行技术分享和技术培训,带动团队技术氛围
** 任职要求:**
- 本科及以上学历,计算机相关专业,基础知识扎实,拥有5年以上web开发经验和3年以上项目管理经验
- 精通 JavaScript、HTML、CSS 等原生前端基础技术,熟悉相关规范
- 精通nodejs, 有大型 Node.js 项目的开发和迭代经验
- 深谙 MV* 模式,精通AMP、AngularJs、ReactJS、VueJS、Polymer等任意一种前端框架
- 熟悉数据可视化库,如ECharts/D3.js/HighCharts等任意一种
- 熟悉MySQL, Postgres等数据库,熟悉Redis等缓存优化
- 希望加入一家快速成长的金融行业创业公司
工作地点:北京市 东城区 来福士 来福士中心办公楼2002B
联系方式: 欢迎砸来简历:sean.wu@bigonelab.com 邮件标题注明“BigOne Lab求职 + 姓名” 请写一两句介绍自己的话 谢谢!!
↧
为什么我的result.isAdmin没有值呢
↧
↧
招聘游戏服务器开发工程师和前端开发工程师
服务器开发工程师(base:北京) 工作职责:
- 负责产品后端功能模块开发,维护;
- 后端原有功能的重构升级和效率优化;
- 优化开发阶段和维护阶段DevOps工具链;
- 与产品经理紧密沟通,收集反馈,实现产品特性的快速迭代。 职位要求:
- 有游戏服务器主程经历,线上实际运营游戏经验;
- 具有devops经验和落地能力;
- 熟悉 Node.js 开发,JavaScript 基本概念清晰,熟练掌握闭包、回调、Promise,熟悉Pomelo框架,熟悉Express / Koa 等常用框架;
- 了解 ES6 / ES7 / Babel 等新技术;
- 熟练掌握 Git 版本控制工具;
- 熟悉常见设计模式和编程最佳实践;
高级前端工程师(base:北京) 工作职责: 1、负责PC端、手机移动,Web App前端开发、交互实现及性能优化工作; 2、主体开发工作基于React的Web App; 3、研究并改善产品,优化产品的用户体验,兼容各类浏览器及性能优化; 4、与后端工程师协作,高效完成产品的数据交互、动态数据展现。 任职要求: 1、5年互联网开发经验; 2、出色的编码能力,熟悉Typescript,熟悉常用的算法,熟悉开源框架,解决问题能力强; 3、掌握下列技术栈的大部分,React/React-router/redux/tslint; 4、熟悉敏捷开发及相关技术工具:单元测试,Git流程,CI/CD框架; 5、掌握Javascript、CSS3、HTML5,对Javascript及Typescript的语言特性有比较深入的理解,熟悉使用ES6标准; 6、掌握自动单元测试和集成测试的技术和流程,熟悉 jest/enzyme; 7、掌握前端UI框架,如Bootstrap, AdminLTE等,有实现复杂可复用自定义前段框架组件经验; 8、掌握前端优化技术,如Caching; 9、熟练使用Webpack/Browserify等工具,熟悉前端项目工程化的流程和方法; 10、熟悉模块化开发的思想,有良好的视觉审美品味; 11、创业团队,有能力承担较高强度的开发工作; 12、热衷于对前沿技术的探索。 有兴趣者,请联系18810519507,电微同号。或者邮件nick.wang@optionschina.com.cn
↧
当当网双十二大部分书籍5折后,满200减30,优惠码 QUJD3E
当当网双十二大部分书籍5折后,满200减30,优惠码 QUJD3E
↧
社区推荐的安卓版客户端为啥不能回复
社区推荐的安卓版客户端为啥不能回复,老是没有找到资源,谁知道的
↧
后来,后来,我发现我的硬盘不够了
我找啊找,找不到几个大文件。 后来啊,我就知道了,那就是很多小文件。 自从我做了nodejs开发,我的硬盘就开始被蚕食。 一个项目500M,一个项目500M。 我的空间一去不复返。 我的小姐姐要搬家。
↧
↧
不容错过的 Node.js 项目架构
原文:https://softwareontheroad.com/ideal-nodejs-project-structure/
作者:Sam Quinn
译者:五月君
更多优质文章:关注公众号 “Nodejs技术栈”,开源项目 “https://www.nodejs.red/”
Express.js 是用于开发 Node.js REST API 的优秀框架,但是它并没有为您提供有关如何组织 Node.js 项目的任何线索。
虽然听起来很傻,但这确实是个问题。
正确的组织 Node.js 项目结构将避免重复代码、提高服务的稳定性和扩展性。
这篇文章是基于我多年来在处理一些糟糕的 Node.js 项目结构、不好的设计模式以及无数个小时的代码重构经验的探索研究。
如果您需要帮助调整 Node.js 项目架构,只需给我发一封信 sam@softwareontheroad.com。
目录
- 目录结构
- 三层架构
- 服务层
- Pub/Sub 层 ️️️️️️
- 依赖注入
- 单元测试
- Cron Jobs 和重复任务 ⚡
- 配置和密钥
- Loaders ️
目录结构
这是我要谈论的 Node.js 项目结构。
我在构建的每个 Node.js REST API 服务中都使用了下面这个结构,让我们了解下每个组件的功能。
src
│ app.js # App 入口
└───api # Express route controllers for all the endpoints of the app
└───config # 环境变量和配置相关
└───jobs # 对于 agenda.js 的任务调度定义
└───loaders # 将启动过程拆分为模块
└───models # 数据库模型
└───services # 所有的业务逻辑应该在这里
└───subscribers # 异步任务的事件处理程序
└───types # 对于 Typescript 的类型声明文件(d.ts)
以上不仅仅是组织 JavaScript 文件的一种方式…
三层架构
其思想是使用关注点分离原则将业务逻辑从 Node.js API 路由中移开。
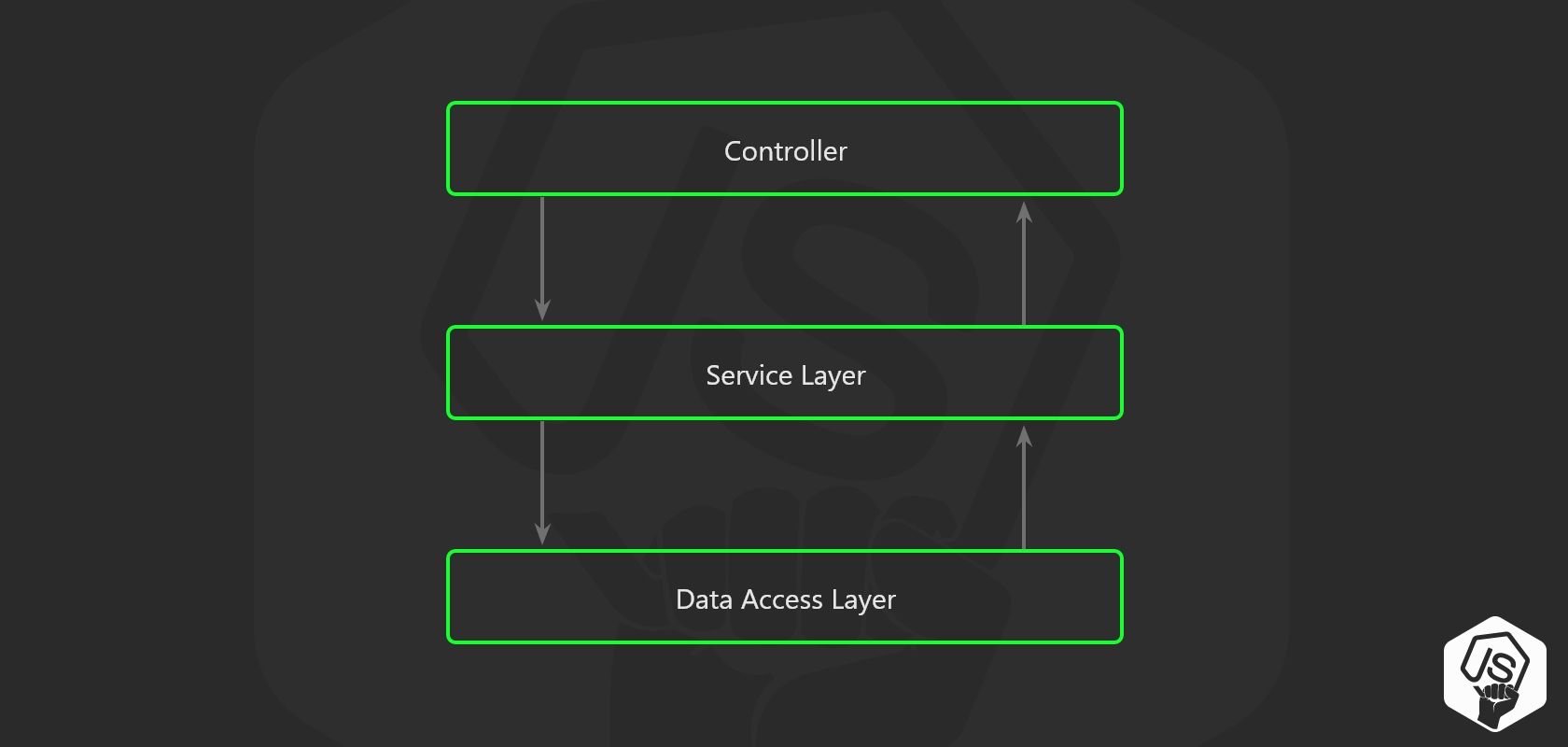
因为有一天,您将希望在一个 CLI 工具上来使用您的业务逻辑,又或从来不使用。对于一些重复的任务,然后从 Node.js 服务器上对它自己进行调用,显然这不是一个好的主意。
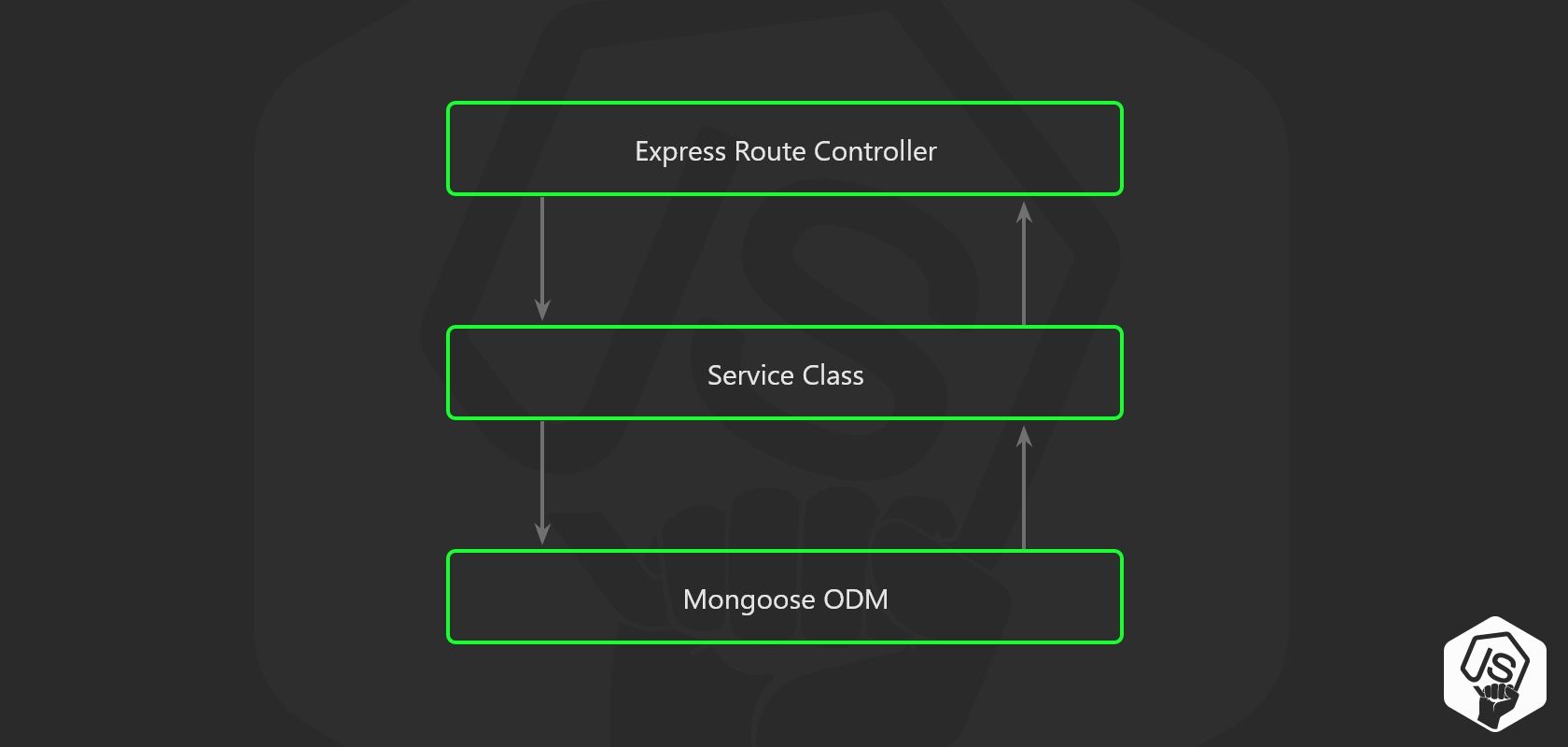
☠️ 不要将您的业务逻辑放入控制器中!! ☠️
你可能想用 Express.js 的 Controllers 层来存储应用层的业务逻辑,但是很快你的代码将会变得难以维护,只要你需要编写单元测试,就需要编写 Express.js req 或 res 对象的复杂模拟。
判断何时应该发送响应以及何时应该在 “后台” 继续处理(例如,将响应发送到客户端之后),这两个问题比较复杂。
route.post('/', async (req, res, next) => {
// 这应该是一个中间件或者应该由像 Joi 这样的库来处理
// Joi 是一个数据校验的库 github.com/hapijs/joi
const userDTO = req.body;
const isUserValid = validators.user(userDTO)
if(!isUserValid) {
return res.status(400).end();
}
// 这里有很多业务逻辑...
const userRecord = await UserModel.create(userDTO);
delete userRecord.password;
delete userRecord.salt;
const companyRecord = await CompanyModel.create(userRecord);
const companyDashboard = await CompanyDashboard.create(userRecord, companyRecord);
...whatever...
// 这就是把一切都搞砸的“优化”。
// 响应被发送到客户端...
res.json({ user: userRecord, company: companyRecord });
// 但代码块仍在执行 :(
const salaryRecord = await SalaryModel.create(userRecord, companyRecord);
eventTracker.track('user_signup',userRecord,companyRecord,salaryRecord);
intercom.createUser(userRecord);
gaAnalytics.event('user_signup',userRecord);
await EmailService.startSignupSequence(userRecord)
});
将业务逻辑用于服务层
这一层是放置您的业务逻辑。
遵循适用于 Node.js 的 SOLID 原则,它只是一个具有明确目的的类的集合。
这一层不应存在任何形式的 “SQL 查询”,可以使用数据访问层。
- 从 Express.js 的路由器移除你的代码。
- 不要将 req 或 res 传递给服务层
- 不要从服务层返回任何与 HTTP 传输层相关的信息,例如 status code(状态码)或者 headers
例子
route.post('/',
validators.userSignup, // 这个中间层负责数据校验
async (req, res, next) => {
// 路由层实际负责的
const userDTO = req.body;
// 调用 Service 层
// 关于如何访问数据层和业务逻辑层的抽象
const { user, company } = await UserService.Signup(userDTO);
// 返回一个响应到客户端
return res.json({ user, company });
});
这是您的服务在后台的运行方式。
import UserModel from '../models/user';
import CompanyModel from '../models/company';
export default class UserService {
async Signup(user) {
const userRecord = await UserModel.create(user);
const companyRecord = await CompanyModel.create(userRecord); // needs userRecord to have the database id
const salaryRecord = await SalaryModel.create(userRecord, companyRecord); // depends on user and company to be created
...whatever
await EmailService.startSignupSequence(userRecord)
...do more stuff
return { user: userRecord, company: companyRecord };
}
}
发布与订阅层 ️
pub/sub 模式超出了这里提出的经典的 3 层架构,但它非常有用。
现在创建一个用户的简单 Node.js API 端点,也许是调用第三方服务,也许是一个分析服务,也许是开启一个电子邮件序列。
不久之后,这个简单的 “创建” 操作将完成几件事,最终您将获得 1000 行代码,所有这些都在一个函数中。
这违反了单一责任原则。
因此,最好从一开始就将职责划分,以使您的代码保持可维护性。
import UserModel from '../models/user';
import CompanyModel from '../models/company';
import SalaryModel from '../models/salary';
export default class UserService() {
async Signup(user) {
const userRecord = await UserModel.create(user);
const companyRecord = await CompanyModel.create(user);
const salaryRecord = await SalaryModel.create(user, salary);
eventTracker.track(
'user_signup',
userRecord,
companyRecord,
salaryRecord
);
intercom.createUser(
userRecord
);
gaAnalytics.event(
'user_signup',
userRecord
);
await EmailService.startSignupSequence(userRecord)
...more stuff
return { user: userRecord, company: companyRecord };
}
}
强制调用依赖服务不是一个好的做法。
一个最好的方法是触发一个事件,即 “user_signup”,像下面这样已经完成了,剩下的就是事件监听者的事情了。
import UserModel from '../models/user';
import CompanyModel from '../models/company';
import SalaryModel from '../models/salary';
export default class UserService() {
async Signup(user) {
const userRecord = await this.userModel.create(user);
const companyRecord = await this.companyModel.create(user);
this.eventEmitter.emit('user_signup', { user: userRecord, company: companyRecord })
return userRecord
}
}
现在,您可以将事件处理程序/侦听器拆分为多个文件。
eventEmitter.on('user_signup', ({ user, company }) => {
eventTracker.track(
'user_signup',
user,
company,
);
intercom.createUser(
user
);
gaAnalytics.event(
'user_signup',
user
);
})
eventEmitter.on('user_signup', async ({ user, company }) => {
const salaryRecord = await SalaryModel.create(user, company);
})
eventEmitter.on('user_signup', async ({ user, company }) => {
await EmailService.startSignupSequence(user)
})
你可以将 await 语句包装到 try-catch 代码块中,也可以让它失败并通过 ‘unhandledPromise’ 处理 process.on(‘unhandledRejection’,cb)。
依赖注入
DI 或控制反转(IoC)是一种常见的模式,通过 “注入” 或通过构造函数传递类或函数的依赖关系,有助于代码的组织。
通过这种方式,您可以灵活地注入“兼容的依赖项”,例如,当您为服务编写单元测试时,或者在其他上下文中使用服务时。
没有 DI 的代码
import UserModel from '../models/user';
import CompanyModel from '../models/company';
import SalaryModel from '../models/salary';
class UserService {
constructor(){}
Sigup(){
// Caling UserMode, CompanyModel, etc
...
}
}
带有手动依赖项注入的代码
export default class UserService {
constructor(userModel, companyModel, salaryModel){
this.userModel = userModel;
this.companyModel = companyModel;
this.salaryModel = salaryModel;
}
getMyUser(userId){
// models available throug 'this'
const user = this.userModel.findById(userId);
return user;
}
}
在您可以注入自定义依赖项。
import UserService from '../services/user';
import UserModel from '../models/user';
import CompanyModel from '../models/company';
const salaryModelMock = {
calculateNetSalary(){
return 42;
}
}
const userServiceInstance = new UserService(userModel, companyModel, salaryModelMock);
const user = await userServiceInstance.getMyUser('12346');
服务可以拥有的依赖项数量是无限的,当您添加一个新服务时,重构它的每个实例化是一项乏味且容易出错的任务。这就是创建依赖注入框架的原因。
这个想法是在类中定义你的依赖,当你需要一个类的实例时只需要调用 “Service Locator” 即可。
现在让我们来看一个使用 TypeDI 的 NPM 库示例,以下 Node.js 示例将引入 DI。
可以在官网查看更多关于 TypeDI 的信息。
https://www.github.com/typestack/typedi
typescript 示例
import { Service } from 'typedi';
@Service()
export default class UserService {
constructor(
private userModel,
private companyModel,
private salaryModel
){}
getMyUser(userId){
const user = this.userModel.findById(userId);
return user;
}
}
services/user.ts
现在 TypeDI 将负责解决 UserService 需要的任何依赖项。
import { Container } from 'typedi';
import UserService from '../services/user';
const userServiceInstance = Container.get(UserService);
const user = await userServiceInstance.getMyUser('12346');
滥用 service locator 调用是一种 anti-pattern(反面模式)
依赖注入与 Express.js 结合实践
在 Express.js 中使用 DI 是 Node.js 项目体系结构的最后一个难题。
路由层
route.post('/',
async (req, res, next) => {
const userDTO = req.body;
const userServiceInstance = Container.get(UserService) // Service locator
const { user, company } = userServiceInstance.Signup(userDTO);
return res.json({ user, company });
});
太好了,项目看起来很棒!它是如此的有条理,使我现在想编码。
单元测试示例
通过使用依赖项注入和这些组织模式,单元测试变得非常简单。
你不必模拟 req/res 对象或 require(…) 调用。
示例:用户注册方法的单元测试
tests/unit/services/user.js
import UserService from '../../../src/services/user';
describe('User service unit tests', () => {
describe('Signup', () => {
test('Should create user record and emit user_signup event', async () => {
const eventEmitterService = {
emit: jest.fn(),
};
const userModel = {
create: (user) => {
return {
...user,
_id: 'mock-user-id'
}
},
};
const companyModel = {
create: (user) => {
return {
owner: user._id,
companyTaxId: '12345',
}
},
};
const userInput= {
fullname: 'User Unit Test',
email: 'test@example.com',
};
const userService = new UserService(userModel, companyModel, eventEmitterService);
const userRecord = await userService.SignUp(teamId.toHexString(), userInput);
expect(userRecord).toBeDefined();
expect(userRecord._id).toBeDefined();
expect(eventEmitterService.emit).toBeCalled();
});
})
})
Cron Jobs 和重复任务 ⚡
因此,既然业务逻辑封装到了服务层中,那么从 Cron job 中使用它就更容易了。
您不应该依赖 Node.js setTimeout 或其他延迟代码执行的原始方法,而应该依赖于一个将您的 Jobs 及其执行持久化到数据库中的框架。
这样您将控制失败的 Jobs 和一些成功者的反馈,可参考我写的关于最佳 Node.js 任务管理器 https://softwareontheroad.com/nodejs-scalability-issues/
配置和密钥
遵循经过测试验证适用于 Node.js 的 Twelve-Factor App(十二要素应用 https://12factor.net/)概念,这是存储 API 密钥和数据库链接字符串的最佳实践,它是用的 dotenv。
放置一个 .env 文件,这个文件永远不能提交(但它必须与默认值一起存在于存储库中),然后,这个 dotenv NPM 包将会加载 .env 文件并将里面的变量写入到 Node.js 的 process.env 对象中。
这就足够了,但是,我想增加一个步骤。有一个 config/index.ts 文件,其中 NPM 包 dotenv 加载 .env
文件,然后我使用一个对象存储变量,因此我们具有结构和代码自动完成功能。
config/index.js
const dotenv = require('dotenv');
// config() 将读取您的 .env 文件,解析其中的内容并将其分配给 process.env
dotenv.config();
export default {
port: process.env.PORT,
databaseURL: process.env.DATABASE_URI,
paypal: {
publicKey: process.env.PAYPAL_PUBLIC_KEY,
secretKey: process.env.PAYPAL_SECRET_KEY,
},
paypal: {
publicKey: process.env.PAYPAL_PUBLIC_KEY,
secretKey: process.env.PAYPAL_SECRET_KEY,
},
mailchimp: {
apiKey: process.env.MAILCHIMP_API_KEY,
sender: process.env.MAILCHIMP_SENDER,
}
}
这样,您可以避免使用 process.env.MY_RANDOM_VAR 指令来充斥代码,并且通过自动补全,您不必知道如何命名环境变量。
Loaders ️
我从 W3Tech 的微框架中采用这种模式,但并不依赖于它们的包装。
这个想法是将 Node.js 的启动过程拆分为可测试的模块。
让我们看一下经典的 Express.js 应用初始化
const mongoose = require('mongoose');
const express = require('express');
const bodyParser = require('body-parser');
const session = require('express-session');
const cors = require('cors');
const errorhandler = require('errorhandler');
const app = express();
app.get('/status', (req, res) => { res.status(200).end(); });
app.head('/status', (req, res) => { res.status(200).end(); });
app.use(cors());
app.use(require('morgan')('dev'));
app.use(bodyParser.urlencoded({ extended: false }));
app.use(bodyParser.json(setupForStripeWebhooks));
app.use(require('method-override')());
app.use(express.static(__dirname + '/public'));
app.use(session({ secret: process.env.SECRET, cookie: { maxAge: 60000 }, resave: false, saveUninitialized: false }));
mongoose.connect(process.env.DATABASE_URL, { useNewUrlParser: true });
require('./config/passport');
require('./models/user');
require('./models/company');
app.use(require('./routes'));
app.use((req, res, next) => {
var err = new Error('Not Found');
err.status = 404;
next(err);
});
app.use((err, req, res) => {
res.status(err.status || 500);
res.json({'errors': {
message: err.message,
error: {}
}});
});
... more stuff
... maybe start up Redis
... maybe add more middlewares
async function startServer() {
app.listen(process.env.PORT, err => {
if (err) {
console.log(err);
return;
}
console.log(`Your server is ready !`);
});
}
// Run the async function to start our server
startServer();
如您所见,应用程序的这一部分可能真是一团糟。
这是一种有效的处理方法。
const loaders = require('./loaders');
const express = require('express');
async function startServer() {
const app = express();
await loaders.init({ expressApp: app });
app.listen(process.env.PORT, err => {
if (err) {
console.log(err);
return;
}
console.log(`Your server is ready !`);
});
}
startServer();
现在目的很明显 loaders 仅仅是一个小文件。
loaders/index.js
import expressLoader from './express';
import mongooseLoader from './mongoose';
export default async ({ expressApp }) => {
const mongoConnection = await mongooseLoader();
console.log('MongoDB Intialized');
await expressLoader({ app: expressApp });
console.log('Express Intialized');
// ... more loaders can be here
// ... Initialize agenda
// ... or Redis, or whatever you want
}
The express loader
loaders/express.js
import * as express from 'express';
import * as bodyParser from 'body-parser';
import * as cors from 'cors';
export default async ({ app }: { app: express.Application }) => {
app.get('/status', (req, res) => { res.status(200).end(); });
app.head('/status', (req, res) => { res.status(200).end(); });
app.enable('trust proxy');
app.use(cors());
app.use(require('morgan')('dev'));
app.use(bodyParser.urlencoded({ extended: false }));
// ...More middlewares
// Return the express app
return app;
})
The mongo loader
loaders/mongoose.js
import * as mongoose from 'mongoose'
export default async (): Promise<any> => {
const connection = await mongoose.connect(process.env.DATABASE_URL, { useNewUrlParser: true });
return connection.connection.db;
}
以上代码可从代码仓库 https://github.com/santiq/bulletproof-nodejs获取。
结论
我们深入研究了经过生产测试的 Node.js 项目结构,以下是一些总结的技巧:
- 使用 3 层架构。
- 不要将您的业务逻辑放入 Express.js 控制器中。
- 使用 Pub/Sub 模式并为后台任务触发事件。
- 进行依赖注入,让您高枕无忧。
- 切勿泄漏您的密码、机密和 API 密钥,请使用配置管理器。
- 将您的 Node.js 服务器配置拆分为可以独立加载的小模块。
↧
兆芯 KX-6000 写nodejs够用吗?
有人用吗?
↧
问一个mongodb的数据库问题
我现在发现我们之前的数据库中有一个字段是这样的 ,
这样的数据我应该这么去查询这数据啊 我一加.就是要查询下级元素中的数据
字段中带点的参数名改这么处理
↧
解锁网易云音乐歌单版权地区限制|使用Proxifier|开机自启动Shell
那天我像往常一样打开网易云音乐,点击首页那张之前创建的中岛美雪的歌单,然后看到了这个:
满屏的灰色打破了我镇定的情绪。
我决定开始行动。
一顿搜索之后发现了这个解决方案:UnblockNeteaseMusic ,赞美作者:nondanee
它的思路是:
- 使用 QQ / 虾米 / 百度 / 酷狗 / 酷我 / 咪咕 / JOOX 音源替换变灰歌曲链接
- 为请求增加
X-Real-IP参数解锁海外版权限制。(因为有些歌曲在国外是可以正常听的)
下面是教程正文
1、安装项目运行环境(Node.js)
Windows
Download | Node.js下载 .msi 安装包并安装
macOS
Download | Node.js下载 .pkg 安装包并安装
Linux
Installing Node.js via package manager | Node.js
当然用 macOS 的 Homebrew,Windows 的 Scoop 等包管理器安装也可以,根据个人喜好选择即可。
Android 平台的终端模拟器如 Termux,NeoTerm 等也可以安装 Node.js,教程非常多,请善用搜索引擎。
2、下载项目|两种方法
- 使用 Git 克隆
git clone https://github.com/nondanee/UnblockNeteaseMusic.git #克隆项目仓库
cd UnblockNeteaseMusic #进入项目根目录
- 手动下载源码压缩包:在项目首页点击 Clone or download 绿色按钮,选择 Download ZIP 并解压
P.S. 项目不需要安装任何依赖(前端同学不要手快npm install或者yarn)。
使用此项目存在两种方法,或者说两种模式。下面分别介绍:
3.1、方法1代理模式(亲测可用)
首先配置Proxifier
添加一个后面用到的Proxies:只需要填AddresssPortProtocol,其他的空着。
然后添加一个Rules:注意那个+按钮,点击后选择网易云音乐,然后Applications框里就会出现内容。我们的内容或许不同,没问题。其他地方和我这边保持一致即可。Action选择你在上一步添加的那个。
*.music.126.net;*.music.163.com;mam.netease.com;api.iplay.163.com
接着Rules右边的 DNS部分,选择Resolve hostname through proxy,其余地方默认即可。
最后,在命令行启动作者的项目:node app.js
现在我们打开网易云客户端会发现,已经可以听因为版权而灰掉的音乐了~
3.2、方法2Hosts模式(亲测失效)
因此不做介绍,感兴趣点击这里了解。
4、设置开机自动运行程序
有没有觉得每次开机都要跑到项目目录下,然后命令行运行node app.js,很烦人?
觉得“没有”的同学,可以关掉本页面了~
思路是写一个shell脚本,脚本里是运行项目的命令,然后在系统设置开机时自动运行此shell脚本。下面是过程:
- 在作者项目目录下新建
launch.sh文件,然后写下此脚本:
#!/bin/sh
cd /Users/xxxxxx/UnblockNeteaseMusic; # 这一行是cd到作者项目的目录,你那边肯定和我的路径不一样,不能照抄。
nohup node ./app.js &
你会注意到上面有个nohup命令,它是让命令行程序可以运行在后台的工具(因为一般在终端运行脚本时,得保持终端开启。关掉终端意味着结束脚本运行。但nohup让脚本可以在终端关闭后可以持续运行。)
P.S. 貌似OSX系统自带有nohup命令,无需安装。
- 赋予此脚本管理员权限:
sudo chmod 777 launch.sh - 打开系统设置、用户与群组、登录项:添加上面那个脚本进来。
- 右键此脚本文件,点击“显示简介”,设置“打开方式”为自己的终端程序(iTerm也行)。
- 重启测试。
所有的折腾(一晚上+中午两小时)都是值得的。(比如可以水一篇博客23333)
↧
↧
怪异的移动端CSS问题之「神秘的白线条」
这是PC端的图:
这是移动端的图(使用PC端Chrome开发工具里的模拟手机功能,但实测真机上问题同样存在)
这是真实项目中的图:(上面两张图是我把真实项目中bug之外的要素全删的结果。)
看到中间的白线条了吗? P.S. 项目里没用img标签,而是background-image。 很奇怪的问题。我通过调整div的height可以在某个值时消除此线条,但设计原因我又不能调整高度。 代码很简单,在这里【注意HTML里面的图片用的是Imgur的图床,因此可能翻墙才能展示。】 这个布局是有点奇怪,可能改变布局能解决此问题。但我现在非常想知道为什么移动端会出现这个问题?怎么造成的?
我做过的尝试:加背景色,会减轻白色线条影响,但仔细看,依旧是能看到白线的。 提前谢谢大家!
↧
超越 google 成为世界第三,eslint-config-alloy 是如何成功的
eslint-config-alloy是腾讯 AlloyTeam 创立的一套 ESLint 规则,自 2017 年 8 月发布第一个版本以来,不知不觉中已经收获到 1.2k stars,超过了 eslint-config-google,成为了世界上排名第三的 ESLint 规范<sup>1</sup>(仅次于 airbnb和 standard)。
两年多以来,我们很少推广,主要靠大家口口相传,自然增长。能够超过 google 的规范,说明它确实受到了开发者的欢迎。那么 eslint-config-alloy到底有什么过人之处呢?
设计理念
随着前端社区的进化,eslint-config-alloy的设计理念也有更迭,如今它的设计理念已经很先进了:
1. 样式相关的规则交给 Prettier 管理
Prettier 是一个代码格式化工具,相比于 ESLint 中的代码格式规则,它提供了更少的选项,但是却更加专业。
如今 Prettier 已经成为前端项目中的必备工具,eslint-config-alloy也没有必要再去维护 ESLint 中的代码格式相关的规则了,所以我们在 v3 版本中彻底去掉了所有 Prettier 相关的规则,ESLint 用来检查它更擅长的逻辑错误了。
至于缩进要两个空格还是四个空格,末尾要不要分号,可以在项目的 prettier.config.js中去配置,当然我们也提供了一份推荐的 Prettier 配置供大家参考。
2. 传承 ESLint 的理念,帮助大家建立自己的规则
大家还记得 ESLint 是怎么打败 JSHint 成为最受欢迎的 js 代码检查工具吗?就是因为 ESLint 推崇的插件化、配置化,满足了不同团队不同技术栈的个性的需求。
所以 eslint-config-alloy也传承了 ESLint 的设计理念,不会强调必须要使用我们这套规则,而是通过文档、示例、测试、网站等方便大家参考 alloy 的规则,在此基础上做出自己的个性化。
由于 React/Vue/TypeScript 插件的文档没有中文化(或中文的版本很滞后),所以 alloy 的文档很大程度上帮助了国内开发者理解和配置个性化的规则。
实际上国内有很多团队或个人公开的 ESLint 配置,都参考了 alloy 的文档。
3. 高度的自动化:先进的规则管理,测试即文档即网站
无情的推动自动化
eslint-config-alloy通过高度的自动化,将一切能自动化管理的过程都交给脚本处理,其中包括了:
- 通过 greenkeeper 和 travis-ci,自动检查 ESLint 及相关插件是否有新版本,新版本中是否有新规则需要我们添加
- 自动检查我们的规则是否包含了 prettier 的规则
- 自动检查我们的规则是否包含了已废弃(deprecated)的规则
除此之外,通过自动化的脚本,我们甚至可以将成百上千个 ESLint 配置文件分而治之,每个规则在一个单独的目录下管理:
- 通过脚本将单个的配置整合成最终的一个配置
- 通过脚本将单个配置中的 description 和 reason 构建成文档网站,方便大家查看
- 通过脚本将单个配置中的
bad.js和good.js输出到网站中,甚至可以直接在网站中看到bad.js的(真实运行 ESLint 脚本后的)报错信息
这样的好处是非常明显的,测试即文档即网站,我们可以只在一个地方维护规则和测试,其他工作都交给自动化脚本,极大的降低了维护的成本。简单来说,当我们有个新规则需要添加时,只需要写三个文件 test/index/another-rule/.eslintrc.js, test/index/another-rule/bad.js, test/index/another-rule/good.js即可。
4. 与时俱进,第一时间跟进最新的规则
ESLint 的更新很快,几乎每周都有一个新版本,有时有新规则,有时会废弃已有规则,而且相关插件(React/Vue/TypeScript)也会时而更新,没有自动化工具的话,实在是难以跟进。
而 eslint-config-alloy通过上述的自动化工具,可以在第一时间就收到 greenkeeper 提的 issue,告诉我们哪个插件更新了,其中的 travis-ci 构建日志会告诉我们哪些规则需要添加:

这样就实现了,在前端社区快速更迭的时候能够及时跟进最新的规则,永远保持 eslint-config-alloy的活力和先进。
如何使用 eslint-config-alloy
Q & A
为什么要重复造轮子
其实我们团队最开始使用 airbnb 规则,但是由于它过于严格,部分规则还是需要个性化,导致后来越改越多,最后决定重新维护一套。经过两年多的打磨,现在 eslint-config-alloy已经非常成熟与先进,也受到了公司内外很多团队的欢迎。
为什么不用 standard
standard 规范认为大家不应该浪费时间在个性化的规范了,而应该整个社区统一一份规范。这种说法有一定道理,但是它是与 ESLint 的设计理念背道而驰的。大家还记得 ESLint 是怎么打败 JSHint 成为最受欢迎的 js 代码检查工具吗?就是因为 ESLint 推崇的插件化、配置化,满足了不同团队不同技术栈的个性的需求。
所以 eslint-config-alloy也传承了 ESLint 的设计理念,不会强调必须要使用我们这套规则,而是通过文档、示例、测试、网站等方便大家参考 alloy 的规则,在此基础上做出自己的个性化。
由于 React/Vue/TypeScript 插件的文档没有中文化(或中文的版本很滞后),所以 alloy 的文档很大程度上帮助了国内开发者理解和配置个性化的规则。
实际上国内有很多团队或个人公开的 ESLint 配置,都参考了 alloy 的文档。
相比于 airbnb 规则有什么优势
- eslint-config-alloy拥有官方维护的 vue、typescript、react+typescript 规则,相比之下 airbnb 的 vue 和 typescript 都是第三方维护的
- 先进性,保证能够与时俱进,前面已经重点提到了
- 方便个性化定制,包含中文讲解和网站示例
你这个确实很好,我还是会选择 airbnb
没关系,eslint-config-alloy从设计理念上就相信不同团队不同项目可以有不同的配置,虽然你选择使用 airbnb,但是当你有个性化配置需求的时候,还是可以来我们网站上参考一下哦~
有什么后续规划吗
最近刚开始做国际化,已经开始有外国友人 star 了,相信金子终会发光的,也欢迎大家提意见、参与贡献。
说明:
<span id=“1”></span>1: 以 stars 数量排名,其中 airbnb 仓库名是 airbnb/javascript故搜索结果中没有
↧
表字段问题
比如我要统计一篇文章的回复数,那我是在文章表里加一个replycount字段,每次用户创建回复时就把这个字段加一,还是使用文章ID去回复表select count(*) from reply where post_id=id呢?
↧
More Pages to Explore .....