没别的意思,交个朋友
↧
苏州的noder看过来
↧
分享一个React版的cnode
在这里非常感谢cnode社区 其实我分享的主要目的是为了让大家帮我review代码的 项目github地址 线上预览收藏和标记消息为已读以及编辑文章功能暂时没有实现
首页

招聘板块

发表主题,这次支持富文本编辑器功能了

获取已读和未读消息

个人中心

查看帖子

支持回复,评论和点赞

支持查看他人资料

支持上拉加载更多
支持登陆退出
↧
↧
接入物流查询功能,需要知道些什么?
↧
记一次 Node.js 内存泄漏排查
首先感谢 alinode 团队 https://alinode.aliyun.com的支持。
大概一个月前,在 alinode 管理页面看到内存占用成锯齿状上升,虽然上涨速度很慢,但是最低点与最高点都在稳定上涨,意识到应该是内存泄漏了。
虽然有关内存泄漏方面的文章读了一些,也知道需要看内存快照,内存时间线等日志来分析内存泄漏,但是真正自己上手时还是有些懵逼了。使用 alinode 将程序运行不同时间点的内存快照导出然后对比分析(这时使用的是 devtools),因为对于 devtools 了解不深,其中显示的各种参数完全看不懂。但是使用 compare 得到的是 closure 有 50K 的新增却没有减少,这时候大概就定位到了这里,开始一层层打开树状图追踪。
从开始追踪就已经一步步走到了坑里,在内存快照中看到了一个函数 onUncaughtException被频繁调用,这个函数是我写给 process.on('uncaughtException')的回调函数。这时候我深信不疑是这里出了问题,也不能说不对,但是真实的错误栈却不在这里,存在另一个地方频繁发生 uncaughtException才导致这里看起有问题,而真正的问题却被我忽略了。
发现问题所在后我就反复的看代码,怎么也没发现有错误出现。在正常工作与查内存泄漏中徘徊了将近一个月。当初是因为对 ONS 有些疑问被一个朋友拉近了一个群,进来就知道这是朴灵大大 Node.js 团队的群了,ONS 的问题直接就没有问,这个群也就淹没在大堆消息里了。昨天突然想起我的内存泄漏问题正是这个群覆盖的范畴,赶紧在群里反应了我的问题,得到了@奕钧的及时响应,先是根据我的截图猜测到是事件重复监听,后又加入我的项目帮忙查看内存快照,最终追查到了真正的问题所在,确实是我的一段代码对 error事件进行反复的监听。
定位到问题再去看代码时瞬间清醒,这样的错误我犯过两次了。可能是 HTTP 处理写习惯了,碰到 TCP 处理时总是忘记创建一个连接池,还是在每次请求时创建新的连接并监听事件。现在记录下这个过程并深刻反思,事不过三。
↧
求教导怎么用 Jest 测试 Koa2 Api Server
最近想要用 Koa2 来制作自己的部落格 Backend api server 先简单地写出一些功能后,想使用 Jest 来做测试,但是发现了许多问题 希望有大大能给小弟一些建议 小弟遇到的问题有以下几个,目前一直都没有好的解法
- 没办法测试 i18n 和 MongoDB:不知道是不是 jest 测试启动的方法不一样,本来应该在 entry file 中导入的 middleware i18n 没有启动到。另外 mongodb 也没有启动到,变得这两边我都要判断 NODE_ENV=test 来略过
- 没办法直接使用 toThrowError 来验证 new Error 的物件
- 没办法测试 api,不知道为什么一直没办法测试 api,有找寻过网路上的范例。但是在 route 那边 log 却没有东西印出来
- 跑测试时 port 会发生互抢的问题,目前不知道问题点是什么,只能先判断如果 port 已被使用就略过
以下是小弟的项目位址 和 jest.config.js 如果有写法上的建议,感谢各位大大交流指教 repository
module.exports = {
bail: true, // Stop test when first test fail
collectCoverage: true,
collectCoverageFrom: ['**/*.{js}'],
coverageDirectory: '<rootDir>/public/coverage',
coveragePathIgnorePatterns: [
'<rootDir>/views/',
'<rootDir>/config/',
'<rootDir>/public/',
'<rootDir>/jest.config.js/',
'<rootDir>/node_modules/',
],
coverageReporters: ['lcov', 'text', 'text-summary'],
coverageThreshold: {
global: {
lines: 100,
branches: 100,
functions: 100,
statements: 100,
},
},
clearMocks: true,
resetMocks: true,
testEnvironment: 'node',
setupFiles: ['<rootDir>/index.js'],
verbose: true,
watchPathIgnorePatterns: [
'<rootDir>/LICENSE',
'<rootDir>/.eslintrc',
'<rootDir>/.gitignore',
'<rootDir>/.eslintignore',
'<rootDir>/node_modules/',
],
};
↧
↧
vue新手问答
跨域jsonp格式怎么回事
↧
请问大家一般用什么来做access control?有什么RBAC的module推荐的么?
我在用expressjs来写一个web app 里面需要用到access control 我目前的功能很简单: 一个user,可以创建一个list,那么他也可以邀请别人来看这个list,也可以邀请别人来编辑这个list(可以删除该list里的某些内容,但不能删除整个list)。 请问怎样做比较好?
请问大家有什么样的access control的库可以推荐的吗?
https://github.com/onury/accesscontrolhttps://github.com/seeden/rbachttps://github.com/DeadAlready/easy-rbac
这是我在google上搜出来的,有人用过吗?能给个评价吗?
↧
nodejs内存泄漏
根据easy-monitor展示的节点,有点蒙了
这个该如何分析呢???
↧
小白上传Excel文件有个问题
const stream = await this.ctx.getFileStream();
const type = stream.fields.type
let info = []
await stream.on('data', data => {
const workbook = XLSX.read(data)
const sheetNames = workbook.SheetNames
const worksheet = workbook.Sheets[sheetNames[0]]
let ref = worksheet['!ref'];
const reg = /[a-zA-Z]/g;
ref = ref.replace(reg, '');
const line = parseInt(ref.split(':')[1]);
switch (type) {
case 'goods':
for (let i = 2; i <= line; i++) {
if (!worksheet['A' + i] && !worksheet['B' + i] && !worksheet['C' + i] && !worksheet['D' + i] && !worksheet['E' + i] && i !== 2) {
break;
}
info.push({.......})
break;
default:
break;
}
})
this.ctx.body = info
我这样写返回还是空数组,放在case下面的话又报404,应该怎么写呀
↧
↧
淘宝直播弹幕爬虫
背景说明
公司有通过淘宝直播间短链接来爬取直播弹幕的需求, 奈何即便google上面也仅找到一个相关的话题, 还没有答案. 所以只能自食其力了.
爬虫的github仓库地址在文末, 我们先看一下爬虫的最终效果:
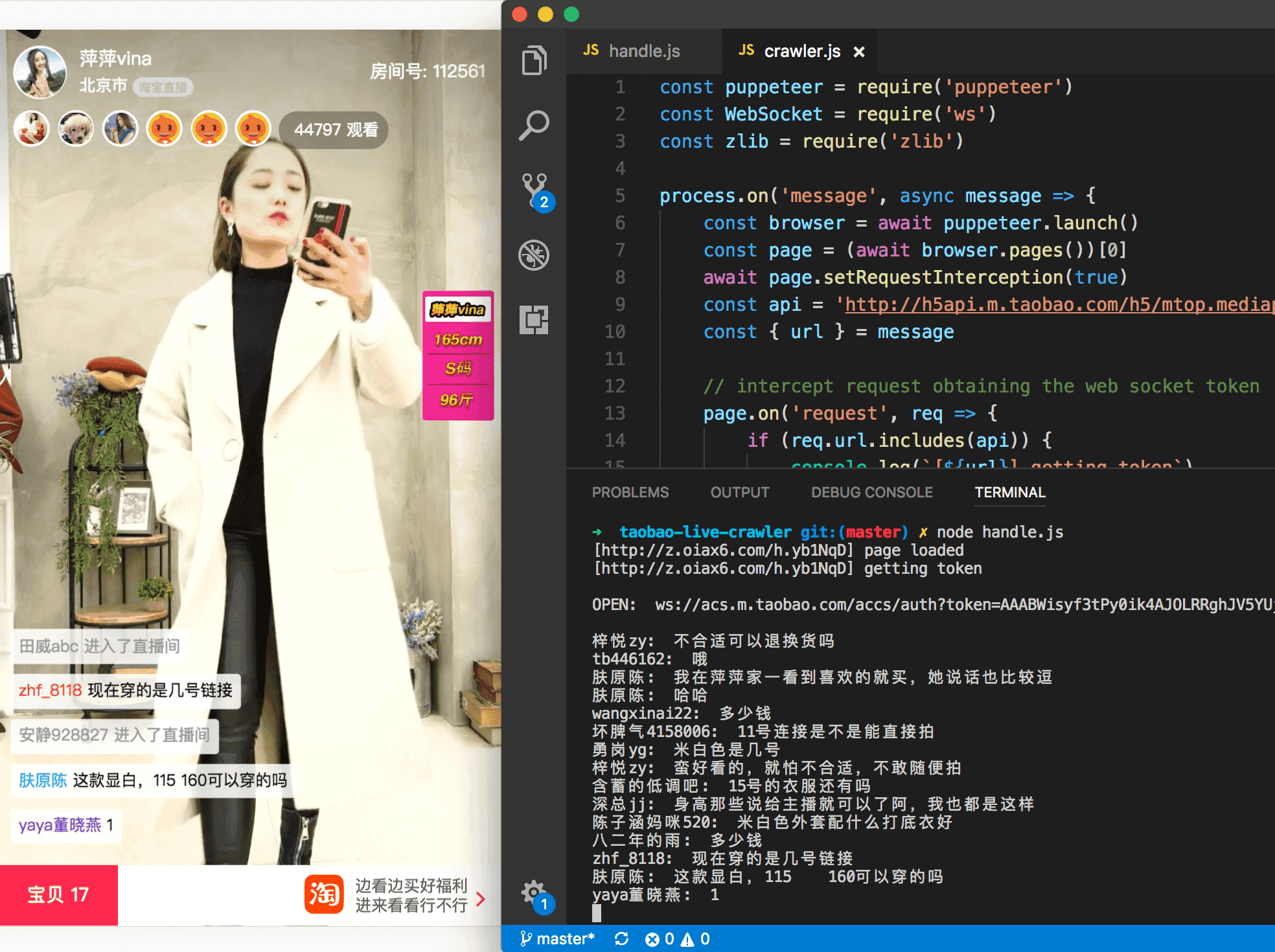
下面我们来抽丝剥茧, 重现一下调研过程.
页面分析
直播间地址在分享直播时可以拿到:

弹幕一般不是websocket就是socket. 我们打开dev tools过滤ws的请求即可看到websocket地址:
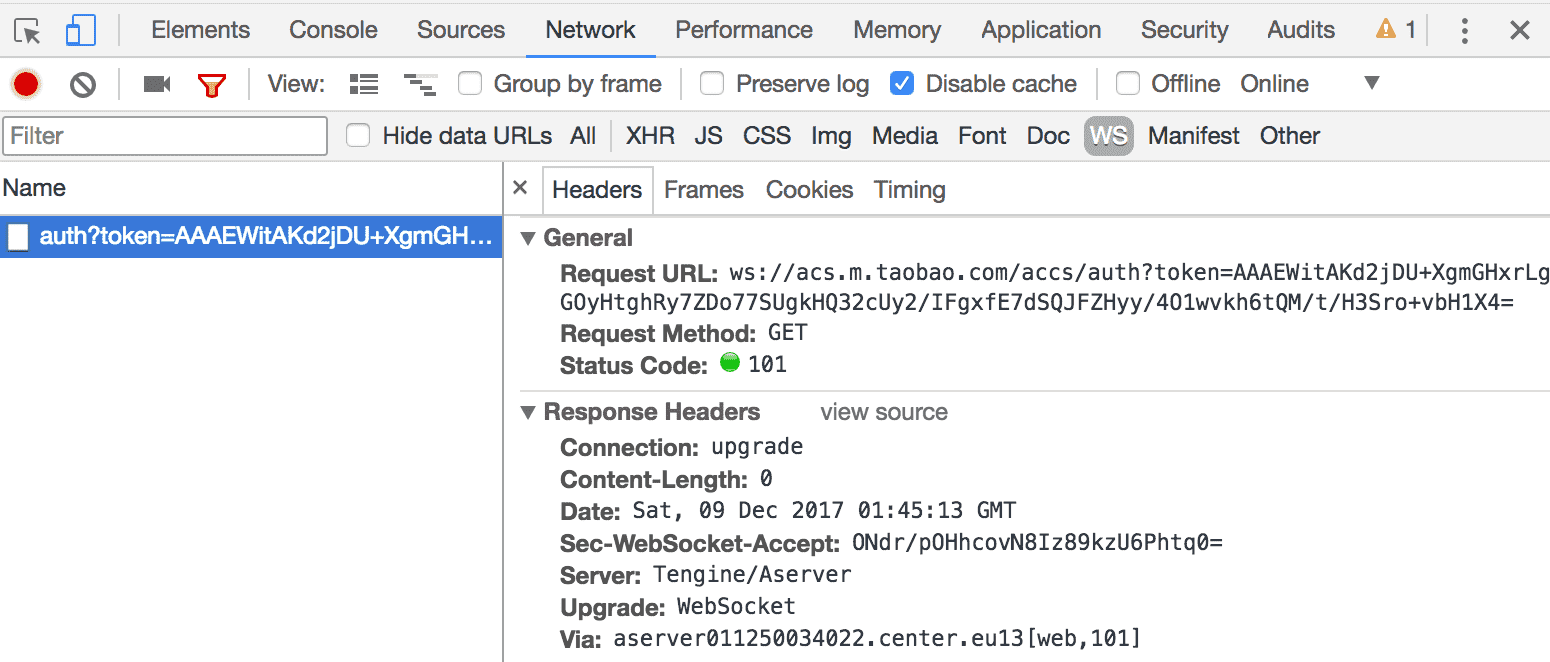
提一下斗鱼: 它走的是flash的socket, 我们就算打开dev tools也是懵逼, 好在斗鱼官方直接开放了socket的API.
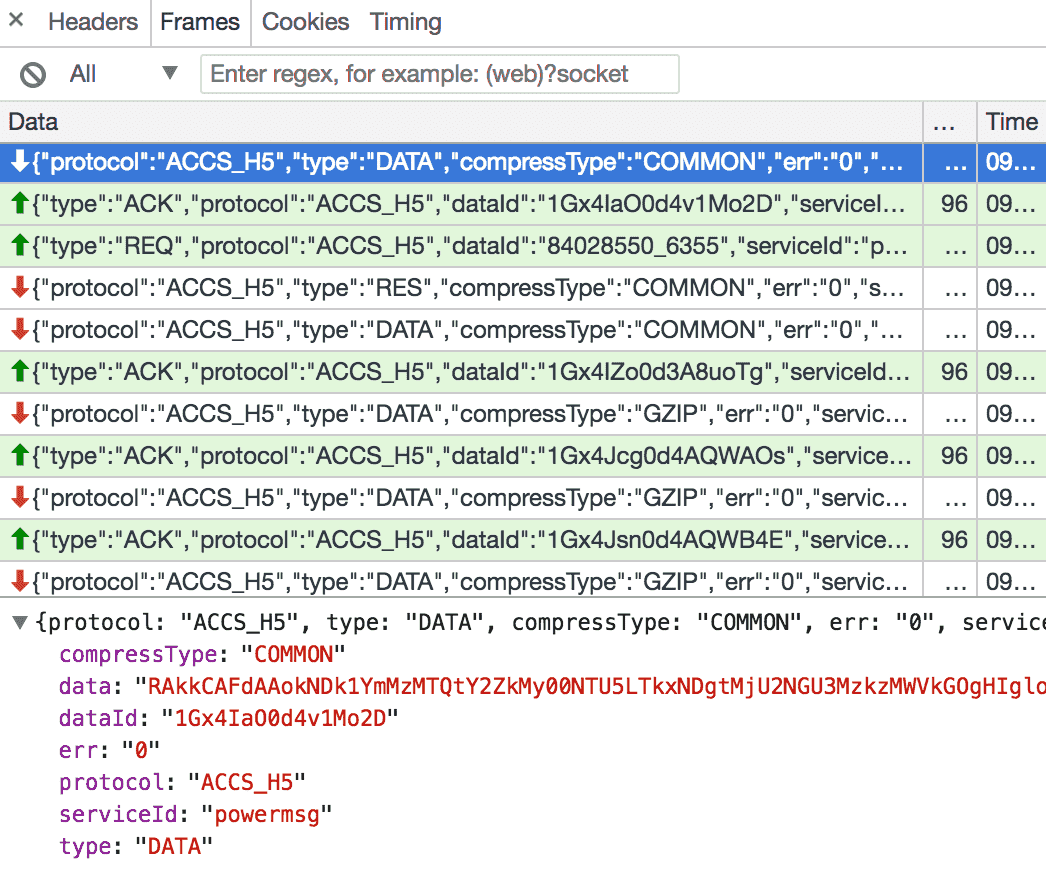
我们继续查看收到的消息, 发现消息的压缩类型compressType有两种: COMMON和GZIP. data的值肯定就是目标消息了, 看起来像经过了base64编码, 解密过程后面再说.
现在我们首先要解决的问题是如何拿到websocket地址. 分析一下html source, 发现可以通过其中不变的部分查找到脚本:
 然鹅, 拿到这块整个的脚本格式化之后发现, 原始代码明显是模块化开发的, 经过了打包压缩. 所以我们只能分析模块内一小块代码, 这是没有意义的.
然鹅, 拿到这块整个的脚本格式化之后发现, 原始代码明显是模块化开发的, 经过了打包压缩. 所以我们只能分析模块内一小块代码, 这是没有意义的.
但是我们可以观察到不同的直播间websocket地址唯一不同的只有token, 所以我们可以想办法拿到token. 当然这是很恶心的环节, 完全没有头绪, 想到的各种可能性都失败了. 后面像无头苍蝇一样看页面发起的请求, 竟然给找到了…
token是通过api请求获取的, api地址是:http://h5api.m.taobao.com/h5/mtop.mediaplatform.live.encryption/1.0/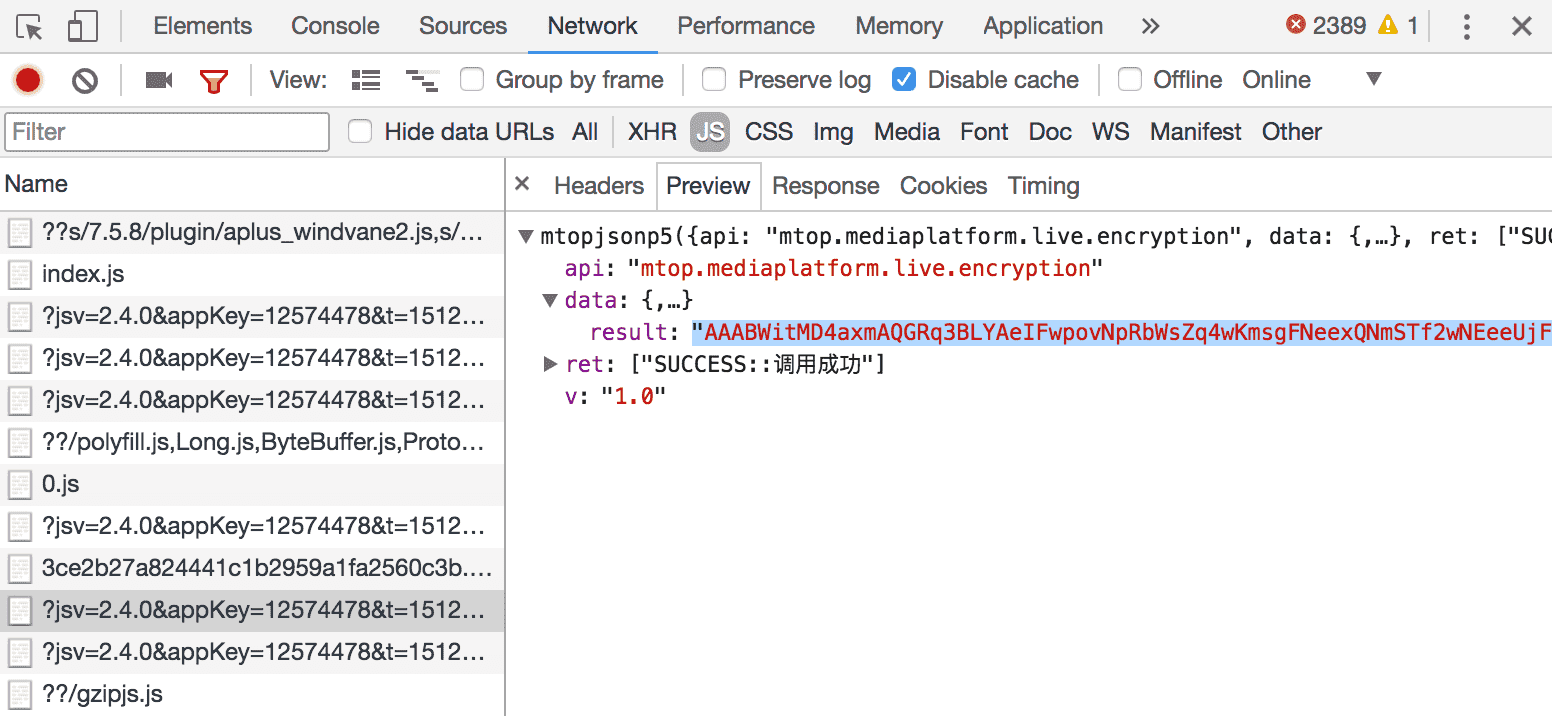
好了那websocket地址的问题解决了, 我们开始写爬虫吧.
编写爬虫
看看api的query string那一堆动态参数, 普通爬虫就别想了, 我们祭出神器: puppeteer. puppeteer是谷歌推出的开放Node API的无头浏览器, 理论上可以可编程化地控制浏览器的各种行为, 对于我们的场景来说就是: 直播页面加载完之后, 拦截获取websocket token的api请求, 解析结果拿到token. 这部分的代码如下:
const browser = await puppeteer.launch()
const page = (await browser.pages())[0]
await page.setRequestInterception(true)
const api = 'http://h5api.m.taobao.com/h5/mtop.mediaplatform.live.encryption/1.0/'
const { url } = message
// intercept request obtaining the web socket token
page.on('request', req => {
if (req.url.includes(api)) {
console.log(`[${url}] getting token`)
}
req.continue()
})
page.on('response', async res => {
if (!res.url.includes(api)) return
const data = await res.text()
const token = data.match(/"result":"(.*?)"/)[1]
const url = `ws://acs.m.taobao.com/accs/auth?token=${token}`
})
// open the taobao live page
await page.goto(url, { timeout: 0 })
console.log(`[${url}] page loaded`)
这里有个性能优化的小技巧. puppeteer官方示例中获取page实例会打开一个新页面:
const page = await browser.newPage(), 实际上浏览器启动本来就默认有个about:blank页面打开, 我们的代码中直接是获取这个打开的实例来跳转直播页面, 这样就可以少一个进程. 可以ps ax|grep puppeteer观察启动的进程数来进行对比, 默认有两个主进程, 剩余的都是页面进程.
获取到websocket地址就可以建立连接拉取消息了:
const url = `ws://acs.m.taobao.com/accs/auth?token=${token}`
const ws = new WebSocket(url)
ws.on('open', () => {
console.log(`\nOPEN: ${url}\n`)
})
ws.on('close', () => {
console.log('DISCONN')
})
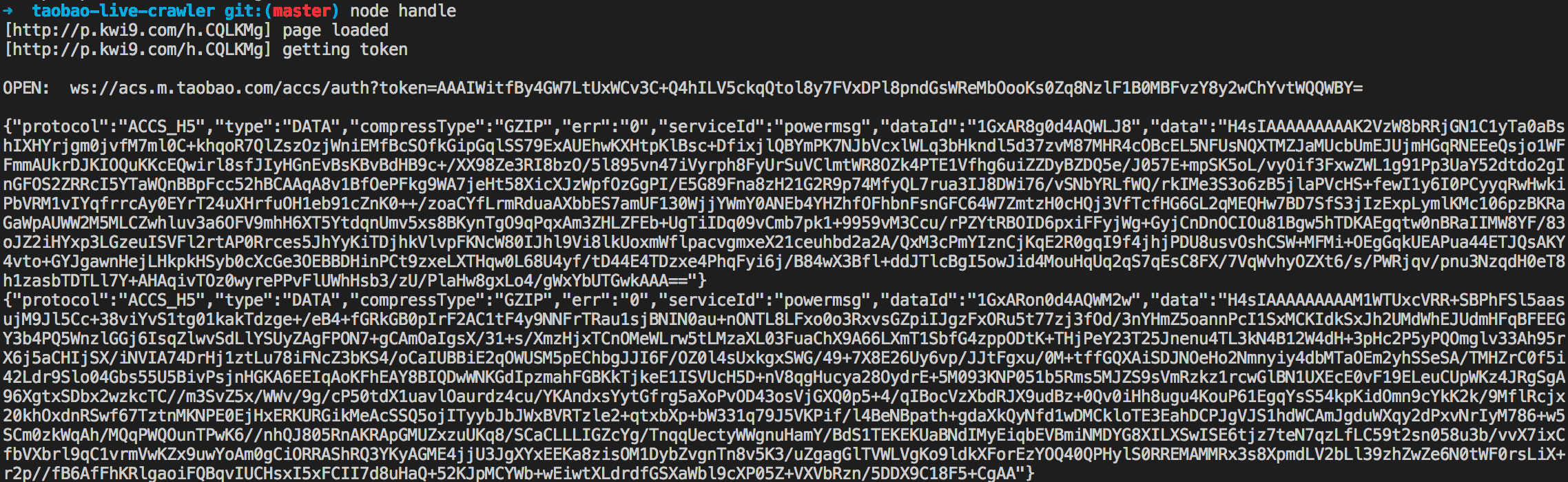
ws.on('message', msg => {
console.log(msg)
})
消息解密
现在我们能持续拉取消息了, 这样会方便分析. 前面我们分析页面的时候发现compressType有两种: COMMON和GZIP. 经过尝试, COMMON的可以直接得到明文, 而GZIP的需要再经过一次gunzip解码. 解码结果大致如下, 里面已经可以看到昵称和弹幕内容了:

然鹅, 一切才刚刚开始…内容里面是有乱码的, 基于这样的内容做正则匹配无果. 如果尝试直接保存buffer或者buffer.toString()到文件会发现文件根本打不开, 内容是无法解析的:

没办法, 我们只能分析原始buffer array的utf8编码了. 这里开了脑洞, 直接将buffer array做join得到的string拿来分析其规律 (分析代码见analyze.js文件):
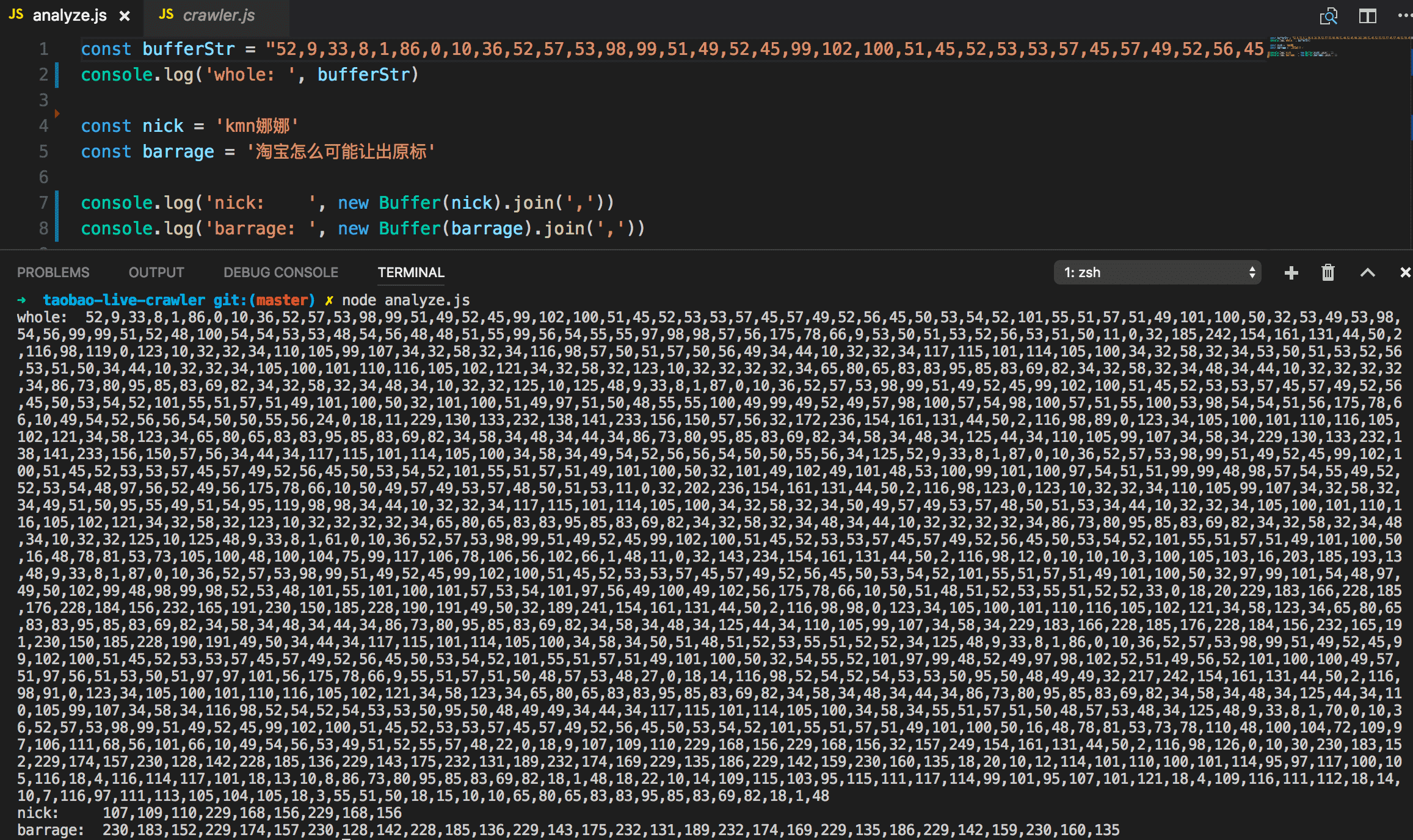
几个样本的分析结果如下, 其中不变的部分做了高亮:
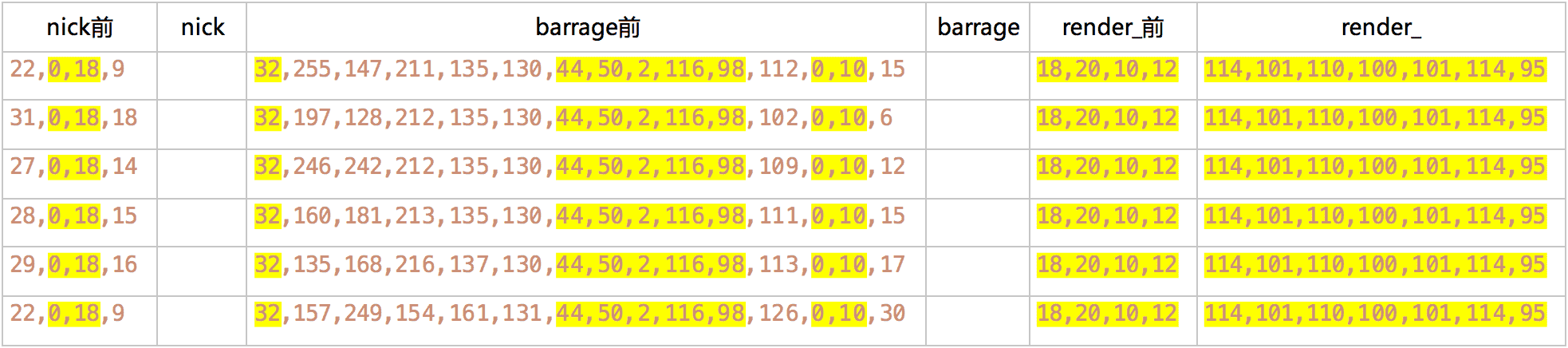
这些值可能是由有效字符编码按一定规则换算过来, 但谁又能猜得到呢, 也没必要.
这样我们就可以通过一个正则表达式解析出nick和barrage了:
/.*,[0-9]+,0,18,[0-9]+,(.*?),32,[0-9]+,[0-9]+,[0-9]+,[0-9]+,[0-9]+,44,50,2,116,98,[0-9]+,0,10,[0-9]+,(.*?),18,20,10,12/
当然这个pattern同样能匹配到关注主播的弹幕, 这不是我们想要的. 我们可以通过一串确定的buffer字符串提前过滤掉这种消息:
const followedPattern = '226,129,130,226,136,176,226,143,135,102,111,108,108,111,119'
至此我们已经可以解析出干干净净的昵称+弹幕了. 完整解密代码如下:
function decode(msg) {
// base64 decode
let buffer = Buffer.from(msg.data, 'base64')
if (msg.compressType === 'GZIP') {
// gzip decode
buffer = zlib.gunzipSync(buffer)
}
const bufferStr = buffer.join(',')
// [followed] notifications are ignored
const followedPattern = '226,129,130,226,136,176,226,143,135,102,111,108,108,111,119'
if (bufferStr.includes(followedPattern)) {
return
}
// // print for debugging
// console.log(bufferStr)
// console.log(buffer.toString())
// first match is nick name and second match is barrage content
const barragePattern = /.*,[0-9]+,0,18,[0-9]+,(.*?),32,[0-9]+,[0-9]+,[0-9]+,[0-9]+,[0-9]+,44,50,2,116,98,[0-9]+,0,10,[0-9]+,(.*?),18,20,10,12/
const matched = bufferStr.match(barragePattern)
if (matched) {
const nick = parseStr(matched[1])
const barrage = parseStr(matched[2])
console.log(`${nick}: ${barrage}`)
}
}
当然可能还存在一个问题, 是关于上面分析结果表里的barrage前, 有连续的5位固定不变, 实际上刚开始是连同前面一位共6位不变的, 结果过了一天之后前面那位从130变到了131, 而再往前的几位变化频率则特别高. 所以我怀疑这些值有可能是跟当前时间有关.
可能不确定的一段时间之后这5位固定值也会变掉吧, 到时正则就得调整了, 但应该可以正常运行很久了. 如有哪些同仁感兴趣, 可以找找规律.
进程维护
实际使用时流程大致应该是这样的: 收到请求之后主进程fork一个爬虫子进程来获取websocket url, 子进程返回结果给主进程, 在使用方建立websocket连接(抢过连接)之后, 子进程便可自杀释放资源, 自杀的同时browser.close()杀死puppeteer相关进程.
之所以这样做是因为测试下来: websocket断开连接不久token会失效.
Github仓库
↧
Hydux: 一个 Elm-like 的 全功能的 Redux 替代品
在学习和使用 Fable + Elmish一段时间之后,对 Elm 架构有了更具体的了解, 和预料中的一样, Elm 风格的框架果然还是和强类型的 Meta Language 语言更搭,只有一个字: 爽。 但是呢,Fable 毕竟是一个小众语言,使用的 F# 语法而且还是来自“万恶”的微软,开发环境还需要依赖 dotnet, 就这几点恐怕在公司的一些正式项目中推行就有些难度。
刚好最近需要做一个答题小游戏的应用,不想再上 React + Redux 全家桶了,一是体积太大,二是无论配置还是写起来都太繁琐。忽然发现 hyperapp让我眼前一亮,简洁的架构,elm 风格, 1kb 的体积,丰富的生态,简直小应用神器! 但是呢,在实际使用中就发现,hyperapp 破坏性更新太多,导致很多第三方库,比如 persist, Redux Devtools, hmr 都不能用了,虽然这些库实现都不复杂,但是一个个改太麻烦了,又不想用老版本,干脆自己重新造了个轮子 – Hydux.
Hydux的语法和 hyperapp 差不多,抽离了 view 层,支持任意的 vdom 库,包括 react, 特点是 内置了 热更新,logger, Redux Devtools和 persist,依然是 1kb大小 (gzip, 不包括开发环境),完全无痛的开发环境,真正的一站式解决方案!

view 层内置了 1kb 的 picodom, 同时也有官方支持的 React 扩展使用 React 来渲染.
说了这么多,还是上点代码: 首先我们有一个 counter 模块,代码和 Elm 的组织方式很类似,不需要像 Redux 在 Actions/Reducers/ActionTypes 中跳来跳去的
// Counter.js
export default {
init: () => ({ count: 1 }), // 初始化状态
actions: { // actions 改变状态
down: () => state => ({ count: state.count - 1 }),
up: () => state => ({ count: state.count + 1 })
},
view: (state: State) => (actions: Actions) => // view
<div>
<h1>{state.count}</h1>
<button onclick={actions.down}>–</button>
<button onclick={actions.up}>+</button>
</div>
}
然后呢,我们可以像 Elm 一样 复用模块, 以前在用 Redux 时总是会面临不知道怎么复用才好的问题,而实际上 Elm 的复用是超级简单和方便的。
import _app from 'hydux'
import withPersist from 'hydux/lib/enhancers/persist'
import withPicodom, { h, React } from 'hydux/lib/enhancers/picodom-render'
import Counter from './counter'
// let app = withPersist<State, Actions>({
// key: 'my-counter-app/v1'
// })(_app)
// use built-in 1kb picodom to render the view.
let app = withPicodom()(_app)
if (process.env.NODE_ENV === 'development') {
// built-in dev tools, without pain.
const devTools = require('hydux/lib/enhancers/devtools').default
const logger = require('hydux/lib/enhancers/logger').default
const hmr = require('hydux/lib/enhancers/hmr').default
app = logger()(app) // 内置的 logger
app = devTools()(app) // 内置的 Redux Devtools 扩展支持
app = hmr()(app) // 内置的热更新模块
}
const actions = {
counter1: Counter.actions,
counter2: Counter.actions,
}
const state = {
counter1: Counter.init(),
counter2: Counter.init(),
}
const view = (state: State) => (actions: Actions) =>
<main>
<h1>Counter1:</h1>
{Counter.view(state.counter1)(actions.counter1)}
<h1>Counter2:</h1>
{Counter.view(state.counter2)(actions.counter2)}
</main>
export default app({
init: () => state,
actions,
view,
})
然后就可以了!简单,可控,无痛的开发环境和代码组织。
异步使用的是类似 Elm 的副作用管理器风格, actions 可以是完全纯的函数,也可以是直接返回一个 promise: https://github.com/hydux/hydux#actions-with-cmd
官网: https://github.com/hydux/hydux
官方支持的 React 扩展: https://github.com/hydux/hydux-react
↧
使用淘宝 registry 镜像安装卡住了。
我是用 vscode 官方工具(
yo code)创建了个 vsc extension 工程。
使用淘宝 registry 镜像安装卡住了。
如何诊断原因?求助江湖豪杰。
↧
分享: 基于kcp写的node(node-addon)代理工具nysocks
TLDR; nysocks是基于kcp提供的nodejs上的SOCKS5代理工具,对丢包的网络环境有较好的效果。
Linode Tokyo 2, JP机房的测试:
tcp代理
nysocks(kcp + libuv) fast
分享一些背景和过程和思考
前几个月看到了kcp和kcptun,觉得很有意思。起初我判断如果要做一个代理工具的话,整体性能不会是最终瓶颈。于是便想用熟悉的node(纯js)一边学习kcp,一边重新写一个代理工具。但最终在性能这块,实际上还是达不到可用的程度,主要有两点:
- node中,v8环境的udp调用,光是在本地收发1MB的数据都需要超过80ms。虽然node在buffer处理上,对脚本而言已经做的很高效了,但在频繁的回调和协议解析和内容拼接上还是远远不够。
- node 8之前的版本没办法设置send/recv(虽然libuv是支持的),需要在操作系统上层面上利用sysctl增大buffer大小。
果然过于底层的应用对脚本来说还是太严苛了。于是我便考虑用c/cpp以node-addon的形式写底层的传输、加密解密部分,顶层还是用node做SOCKS和tcp部分加快开发速度。但我一开始还是担心,因为我知道对于对c/cpp,v8底层,libuv不熟悉的话,写出来的node-addon性能往往还不如用纯js写的代码高。
好在之前看到了Scott Frees的blog和这本电子书 —— C++ and Node.js Integration(需付费)。实践证明,如果你有类似的需求的话,特别是在c/cpp层面进行非阻塞进程的操作及大量buffer在c/cpp和v8之前转换的这种场景,这本书中的内容是非常有效、实用的。
最终的结果还是让我自己满意的,c/cpp部分满足了性能的需求,node部分开发得足够快,也算是让自己找到了对node-addons的定位。但整个项目比我一开始预想的大了太多,精力和经验有限,目前还有非常多可以优化、改进的点。
整个项目大量参考了kcptun和一些非常流行的代理工具,但实现上难以完全保持一直(工作量大)。希望能对有需求的同学和需要类似实现参考的同学一点微小的帮助。
↧
↧
为什么现在Chrome不用翻墙也能更新了?
如题!
↧
Egg如何将token保存在redis中啊?
接触node不久,要使用egg写一些接口给APP调用。第一个遇到的问题就是token的问题了。请问egg中,怎么把token保存在Redis中啊? 有大神知道吗?
↧
TodoKit之前上传的源码 忘记传配置文件了,所以可能下载源码无法运行,现在可以了
注意
- windows客户端会经常出现冻住的情况,Mac正常使用,正在解决,还没找出原因,希望知道的同学指教,推荐使用Mac体验
- 之前忘记传配置文件了,无法运行,现在可以了
- TodoKit 官方产品ID 5a2dde799602c07118887e3c
Built With
Electron、 VueJS、 Electron-VueNodeJS、 ExpressJS、 Socket.IO、 野狗、 七牛云、
客户端源码TodoKit
服务端源码TodoKit-api
↧
写了一个撸 LeetCode 的插件
在 leetcode 可以一键复制 markdown 格式的问题和答案。 这样就很容易把自己的答案保存到 github 上了。
很久之前写的,leetcode 改了新 ui, 相应改了一下。 顺便发布到 chrome webstore 上,居然要交 5 刀才能发布… 搬砖间隙上去刷一刷还是不错的。
项目: https://github.com/4074/leetcode-helper插件地址: https://chrome.google.com/webstore/detail/leetcode-helper/gleoepapfjkpcijfmchfabbnldejdnoj
我的 leetcode solutions: https://github.com/4074/leetcode
↧
↧
test test
test
test
↧
【深圳南山】贝壳旅行招nodejs开发工程师、实习生(13~26K)
具体薪资面议。欢迎2018界毕业小伙伴加入~~
职位描述:
- 参与项目服务器端开发工作,服务器运维及部署工作
- 配合上级交代的其他业务支持工作
职位要求:
1、本科及以上学历,计算机相关专业优先 2、良好的沟通能力和协调能力,有团队合作精神
- 较强的学习能力,有一定的数据结构及算法基础
- 对node.js有一定的了解 5.熟悉linux,熟悉关系型数据库,理解OOP, MVC设计理念
简历投递(推荐):https://www.lagou.com/jobs/3282528.html?source=pl&i=pl-3邮箱投递:beike-hr@shelltrip.club
公司简介:贝壳旅行科技(深圳)有限公司创立于2017年4月,致力于打造全球性的旅行分享社区,创始团队来自BAT,并有成功的创业经历(带领团队从0到1打造了国内第一运动社区,估值超过10亿)! 团队氛围平等自由开放,有爱有理想有面包,欢迎志同道合小伙伴加入,一起创造新的奇迹! 公众号:贝壳旅行助手、贝壳导游之家贝壳旅行APP(Android版本)一款国际旅行图片攻略游记内容的分享平台 原创滤镜图片编辑,海量旅行体验笔记,上万达人聚集入驻 优质攻略,精美游记,趣味标签 旅行,其实简单且有趣
↧
Ubuntu上成功安装Node,部署DOClever接口管理工具成功
DOClever官方介绍
DOClever是一款开源免费的可视化接口管理工具,专业的api接口管理系统,集接口文档、接口自动化测试、Mock数据、团队协作、接口快照等于一身的移动时代首选接口管理平台!
安装Node环境
我的系统是ubuntu16.04,默认直接
sudo apt install nodejs-legacy
命令即可安装,但我们会发现安装的并不是最新版的node,按照官方的说明文档来看,建议安装node最新LST版本;接下来我们开始升级我们的node环境,我们使用npm来进行升级;
安装npm:
sudo apt-get install npm
安装npm n命令:
sudo npm install -g n
安装node8.9.0:
sudo n v8.9.0
我们查看下我们的node版本
node -v
自此最新版Node 8.9.0安装成功了
安装mongodb
安装mongod,ubuntu默认软件源里就有mongodb,我们只需要在命令行输入如下命令即可:
sudo apt-get install mongodb
部署doclever:
首先我们先进入下载的DOClever的源文件根目录
然后在终端运行如下命令
node Server/bin/www
然后我们安装终端提示,输入mongodb数据库名称,upload上传路径、所使用的端口号等
最好我们在浏览器输入http://localhost:端口号即可;
到这里DOClever安装部署就结束了;
其他问题:
部署完成后我们发现,终端命令行窗口不能关闭,关闭后doclever就无法运行了;
我们可以使用forever来守护我们的进程
安装forever
sudo npm install forever -g
用forever启动DOClever
进入doclever安装根目录在终端执行
forever start Server/bin/www
这时我们就可以关闭我们的终端了,DOClever已经在后台运行了
↧

![[LoliHouse] Princess-Session Orchestra - 15 [WebRip 1080p HEVC-10bit...](http://s2.loli.net/2025/04/09/QO618K72ytGZmDJ.webp)







