本文首发于知乎专栏蚂蚁金服体验科技。
首先声明,我在“Bug”字眼上加了引号,自然是为了说明它并非一个真 Bug。
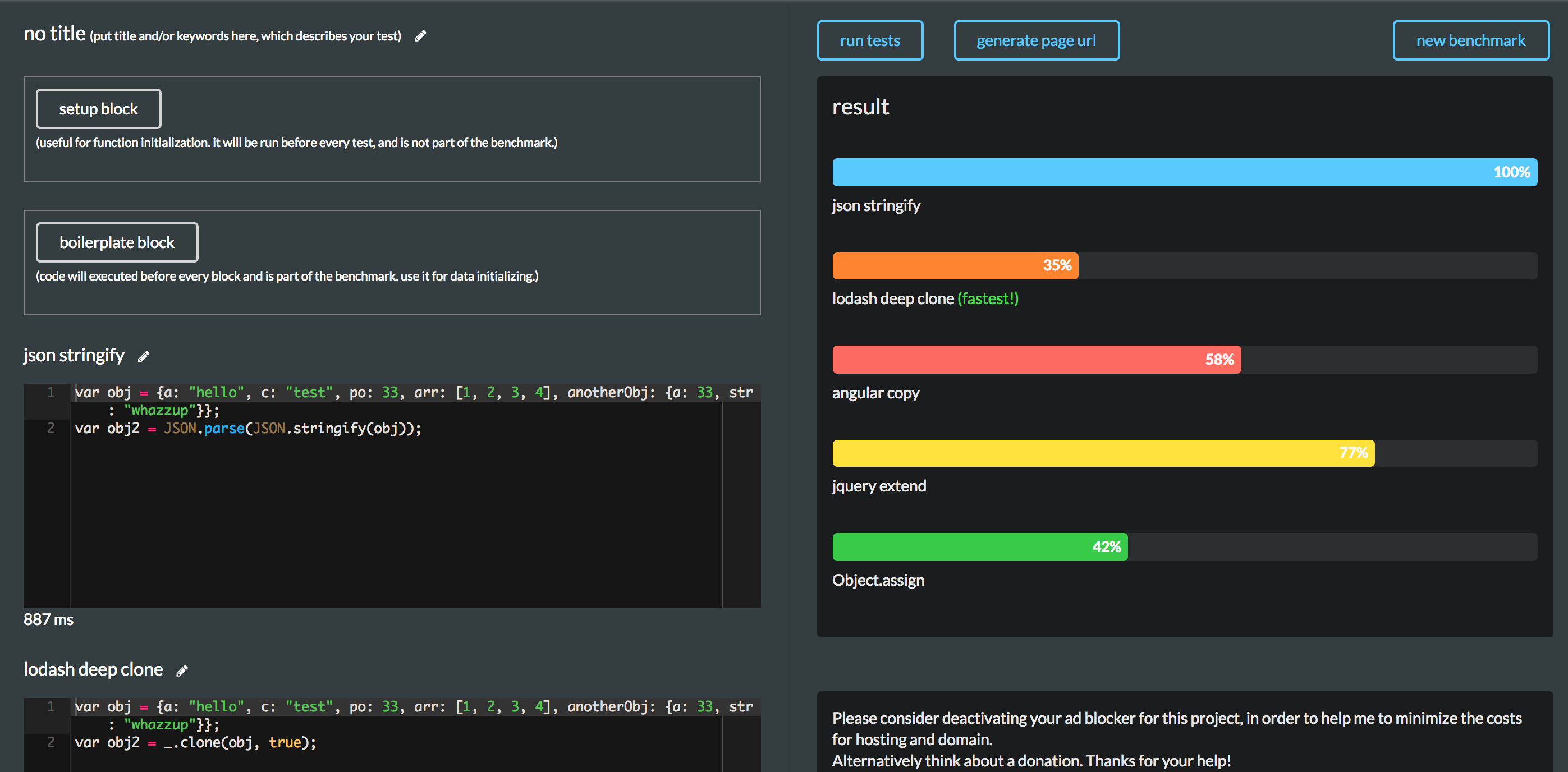
问题抛出
昨天有个童鞋在看后台监控的时候,突然发现了一个错误:
[error] 000001#0: ... upstream prematurely closed connection while reading response header from upstream.
client: 10.10.10.10
server: foo.com
request: "GET /foo/bar?rmicmd,begin run clean docker images job HTTP/1.1"
upstream: "http://..."
大概意思就是说:一台服务器通过 HTTP 协议去请求另一台服务器的时候,单方面被对方服务器断开了连接——并且并没有任何返回。
开始重现
客户端 CURL 指令
其实这次请求的一些猫腻很容易就能发现——在 URL 中有空格。所以我们能简化出一条最简单的 CURL 指令:
$ curl "http://foo/bar baz" -v
**注意:**不带任何转义。
最小 Node.js 源码
好的,那么接下去开始写相应的最简单的 Node.js HTTP 服务端源码。
'use strict';
const http = require('http');
const server = http.createServer(function(req, resp) {
console.log('');
resp.end('hello world');
});
server.listen(5555);
大功告成,启动这段 Node.js 代码,开始试试看上面的指令吧。
如果你也正在跟着尝试这件事情的话,你就会发现 Node.js 的命令行没有输出任何信息,尤其是嘲讽的 '',而在 CURL 的结果中,你将会看见:
$ curl 'http://127.0.0.1:5555/d d' -v
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 5555 (#0)
> GET /d d HTTP/1.1
> Host: 127.0.0.1:5555
> User-Agent: curl/7.54.0
> Accept: */*
>
* Empty reply from server
* Connection #0 to host 127.0.0.1 left intact
curl: (52) Empty reply from server
瞧,Empty reply from server。
Nginx
发现了问题之后,就有另一个问题值得思考了:就 Node.js 会出现这种情况呢,还是其它一些 HTTP 服务器也会有这种情况呢。
于是拿小白鼠 Nginx 做了个实验。我写了这么一个配置:
server {
listen 5555;
location / {
return 200 $uri;
}
}
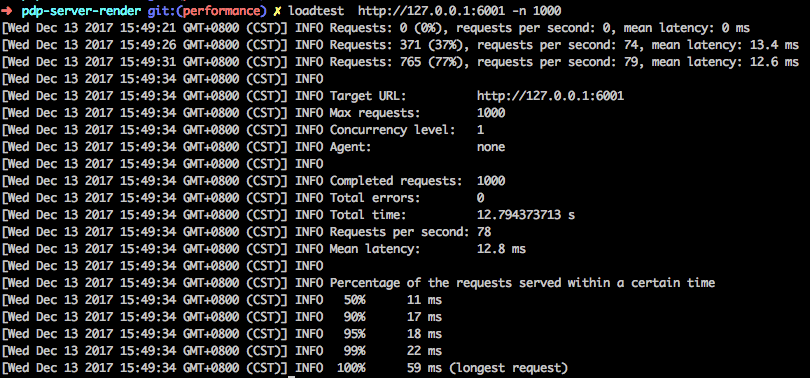
接着也执行一遍 CURL,得到了如下的结果:
$ curl 'http://127.0.0.1:5555/d d' -v
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 5555 (#0)
> GET /d d HTTP/1.1
> Host: 127.0.0.1:5555
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Server: openresty/1.11.2.1
< Date: Tue, 12 Dec 2017 09:07:56 GMT
< Content-Type: application/octet-stream
< Content-Length: 4
< Connection: keep-alive
<
* Connection #0 to host xcoder.in left intact
/d d
![厉害了,我的 Nginx]()
于是乎,理所当然,我暂时将这个事件定性为 Node.js 的一个 Bug。
Node.js 源码排查
认定了它是个 Bug 之后,我就开始了一贯的看源码环节——由于这个 Bug 的复现条件比较明显,我暂时将其定性为“Node.js HTTP 服务端模块在接到请求后解析 HTTP 数据包的时候解析 URI 时出了问题”。
http.js -> _http_server.js -> _http_common.js
源码以 Node.js 8.9.2为准。
这里先预留一下我们能马上想到的 node_http_parser.cc,而先讲这几个文件,是有原因的——这涉及到最后的一个应对方式。
首先看看 lib/http.js的相应源码:
...
const server = require('_http_server');
const { Server } = server;
function createServer(requestListener) {
return new Server(requestListener);
}
那么,马上进入 lib/_http_server.js看吧。
首先是创建一个 HttpParser 并绑上监听获取到 HTTP 数据包后解析结果的回调函数的代码:
const {
parsers,
...
} = require('_http_common');
function connectionListener(socket) {
...
var parser = parsers.alloc();
parser.reinitialize(HTTPParser.REQUEST);
parser.socket = socket;
socket.parser = parser;
parser.incoming = null;
...
state.onData = socketOnData.bind(undefined, this, socket, parser, state);
...
socket.on('data', state.onData);
...
}
function socketOnData(server, socket, parser, state, d) {
assert(!socket._paused);
debug('SERVER socketOnData %d', d.length);
var ret = parser.execute(d);
onParserExecuteCommon(server, socket, parser, state, ret, d);
}
从源码中文我们能看到,当一个 HTTP 请求过来的时候,监听函数 connectionListener()会拿着 Socket 对象加上一个 data事件监听——一旦有请求连接过来,就去执行 socketOnData()函数。
而在 socketOnData()函数中,做的主要事情就是 parser.execute(d)来解析 HTTP 数据包,在解析完成后执行一下回调函数 onParserExecuteCommon()。
至于这个 parser,我们能看到它是从 lib/_http_common.js中来的。
var parsers = new FreeList('parsers', 1000, function() {
var parser = new HTTPParser(HTTPParser.REQUEST);
...
parser[kOnHeaders] = parserOnHeaders;
parser[kOnHeadersComplete] = parserOnHeadersComplete;
parser[kOnBody] = parserOnBody;
parser[kOnMessageComplete] = parserOnMessageComplete;
parser[kOnExecute] = null;
return parser;
});
能看出来 parsers是 HTTPParser的一条 Free List(效果类似于最简易的动态内存池),每个 Parser 在初始化的时候绑定上了各种回调函数。具体的一些回调函数就不细讲了,有兴趣的童鞋可自行翻阅。
这么一来,链路就比较明晰了:
请求进来的时候,Server 对象会为该次请求的 Socket 分配一个 HttpParser对象,并调用其 execute()函数进行解析,在解析完成后调用 onParserExecuteCommon()函数。
node_http_parser.cc
我们在 lib/_http_common.js中能发现,HTTPParser的实现存在于 src/node_http_parser.cc中:
const binding = process.binding('http_parser');
const { methods, HTTPParser } = binding;
至于为什么 const binding = process.binding('http_parser')就是对应到 src/node_http_parser.cc文件,以及这一小节中下面的一些 C++ 源码相关分析,不明白且有兴趣的童鞋可自行去阅读更深一层的源码,或者网上搜索答案,或者我提前无耻硬广一下我快要上市的书《Node.js:来一打 C++ 扩展》——里面也有说明,以及我的有一场知乎 Live《深入理解 Node.js 包与模块机制》。
总而言之,我们接下去要看的就是 src/node_http_parser.cc了。
env->SetProtoMethod(t, "close", Parser::Close);
env->SetProtoMethod(t, "execute", Parser::Execute);
env->SetProtoMethod(t, "finish", Parser::Finish);
env->SetProtoMethod(t, "reinitialize", Parser::Reinitialize);
env->SetProtoMethod(t, "pause", Parser::Pause<true>);
env->SetProtoMethod(t, "resume", Parser::Pause<false>);
env->SetProtoMethod(t, "consume", Parser::Consume);
env->SetProtoMethod(t, "unconsume", Parser::Unconsume);
env->SetProtoMethod(t, "getCurrentBuffer", Parser::GetCurrentBuffer);
如代码片段所示,前文中 parser.execute()所对应的函数就是 Parser::Execute()了。
class Parser : public AsyncWrap {
...
static void Execute(const FunctionCallbackInfo<Value>& args) {
Parser* parser;
...
Local<Object> buffer_obj = args[0].As<Object>();
char* buffer_data = Buffer::Data(buffer_obj);
size_t buffer_len = Buffer::Length(buffer_obj);
...
Local<Value> ret = parser->Execute(buffer_data, buffer_len);
if (!ret.IsEmpty())
args.GetReturnValue().Set(ret);
}
Local<Value> Execute(char* data, size_t len) {
EscapableHandleScope scope(env()->isolate());
current_buffer_len_ = len;
current_buffer_data_ = data;
got_exception_ = false;
size_t nparsed =
http_parser_execute(&parser_, &settings, data, len);
Save();
// Unassign the 'buffer_' variable
current_buffer_.Clear();
current_buffer_len_ = 0;
current_buffer_data_ = nullptr;
// If there was an exception in one of the callbacks
if (got_exception_)
return scope.Escape(Local<Value>());
Local<Integer> nparsed_obj = Integer::New(env()->isolate(), nparsed);
// If there was a parse error in one of the callbacks
// TODO(bnoordhuis) What if there is an error on EOF?
if (!parser_.upgrade && nparsed != len) {
enum http_errno err = HTTP_PARSER_ERRNO(&parser_);
Local<Value> e = Exception::Error(env()->parse_error_string());
Local<Object> obj = e->ToObject(env()->isolate());
obj->Set(env()->bytes_parsed_string(), nparsed_obj);
obj->Set(env()->code_string(),
OneByteString(env()->isolate(), http_errno_name(err)));
return scope.Escape(e);
}
return scope.Escape(nparsed_obj);
}
}
首先进入 Parser的静态 Execute()函数,我们看到它把传进来的 Buffer转化为 C++ 下的 char*指针,并记录其数据长度,同时去执行当前调用的 parser对象所对应的 Execute()函数。
在这个 Execute()函数中,有个最重要的代码,就是:
size_t nparsed =
http_parser_execute(&parser_, &settings, data, len);
这段代码是调用真正解析 HTTP 数据包的函数,它是 Node.js 这个项目的一个自研依赖,叫 http-parser。它独立的项目地址在 https://github.com/nodejs/http-parser,我们本文中用的是 Node.js v8.9.2 中所依赖的源码,应该会有偏差。
http-parser
HTTP Request 数据包体
如果你已经对 HTTP 包体了解了,可以略过这一节。
HTTP 的 Request 数据包其实是文本格式的,在 Raw 的状态下,大概是以这样的形式存在:
方法 URI HTTP/版本
头1: 我是头1
头2: 我是头2
简单起见,这里就写出最基础的一些内容,至于 Body 什么的大家自己找资料看吧。
上面的是什么意思呢?我们看看 CURL 的结果就知道了,实际上对应 curl ... -v的中间输出:
GET /test HTTP/1.1
Host: 127.0.0.1:5555
User-Agent: curl/7.54.0
Accept: */*
所以实际上大家平时在文章中、浏览器调试工具中看到的什么请求头啊什么的,都是以文本形式存在的,以换行符分割。
而——重点来了,导致我们本文所述“Bug”出现的请求,它的请求包如下:
GET /foo bar HTTP/1.1
Host: 127.0.0.1:5555
User-Agent: curl/7.54.0
Accept: */*
重点在第一行:
GET /foo bar HTTP/1.1
源码解析
话不多少,我们之间前往 http-parser 的 http_parser.c看 http_parser_execute ()函数中的状态机变化。
从源码中文我们能看到,http-parser 的流程是从头到尾以 O(n) 的时间复杂度对字符串逐字扫描,并且不后退也不往前跳。
那么扫描到每个字符的时候,都有属于当前的一个状态,如“正在扫描处理 uri”、“正在扫描处理 HTTP 协议并且处理到了 H”、“正在扫描处理 HTTP 协议并且处理到了 HT”、“正在扫描处理 HTTP 协议并且处理到了 HTT”、“正在扫描处理 HTTP 协议并且处理到了 HTTP”、……
![这是回音你懂吗]()
憋笑,这是真的,我们看看代码就知道了:
case s_req_server:
case s_req_server_with_at:
case s_req_path:
case s_req_query_string_start:
case s_req_query_string:
case s_req_fragment_start:
case s_req_fragment:
{
switch (ch) {
case ' ':
UPDATE_STATE(s_req_http_start);
CALLBACK_DATA(url);
break;
case CR:
case LF:
parser->http_major = 0;
parser->http_minor = 9;
UPDATE_STATE((ch == CR) ?
s_req_line_almost_done :
s_header_field_start);
CALLBACK_DATA(url);
break;
default:
UPDATE_STATE(parse_url_char(CURRENT_STATE(), ch));
if (UNLIKELY(CURRENT_STATE() == s_dead)) {
SET_ERRNO(HPE_INVALID_URL);
goto error;
}
}
break;
}
在扫描的时候,如果当前状态是 URI 相关的(如 s_req_path、s_req_query_string等),则执行一个子 switch,里面的处理如下:
- 若当前字符是空格,则将状态改变为
s_req_http_start并认为 URI 已经解析好了,通过宏 CALLBACK_DATA()触发 URI 解析好的事件; - 若当前字符是换行符,则说明还在解析 URI 的时候就被换行了,后面就不可能跟着 HTTP 协议版本的申明了,所以设置默认的 HTTP 版本为
0.9,并修改当前状态,最后认为 URI 已经解析好了,通过宏 CALLBACK_DATA()触发 URI 解析好的事件; - 其余情况(所有其它字符)下,通过调用
parse_url_char()函数来解析一些东西并更新当前状态。(因为哪怕是在解析 URI 状态中,也还有各种不同的细分,如 s_req_path、s_req_query_string)
这里的重点还是当状态为解析 URI 的时候遇到了空格的处理,上面也解释过了,一旦遇到这种情况,则会认为 URI 已经解析好了,并且将状态修改为 s_req_http_start。也就是说,有“Bug”的那个数据包
GET /foo bar HTTP/1.1在解析到 foo后面的空格的时候它就将状态改为 s_req_http_start并且认为 URI 已经解析结束了。
好的,接下来我们看看 s_req_http_start怎么处理:
case s_req_http_start:
switch (ch) {
case 'H':
UPDATE_STATE(s_req_http_H);
break;
case ' ':
break;
default:
SET_ERRNO(HPE_INVALID_CONSTANT);
goto error;
}
break;
case s_req_http_H:
STRICT_CHECK(ch != 'T');
UPDATE_STATE(s_req_http_HT);
break;
case s_req_http_HT:
...
case s_req_http_HTT:
...
case s_req_http_HTTP:
...
case s_req_first_http_major:
...
如代码所见,若当前状态为 s_req_http_start,则先判断当前字符是不是合标。因为就 HTTP 请求包体的格式来看,如果 URI 解析结束的话,理应出现类似 HTTP/1.1的这么一个版本申明。所以这个时候 http-parser 会直接判断当前字符是否为 H。
- 若是
H,则将状态改为 s_req_http_H并继续扫描循环的下一位,同理在 s_req_http_H下若合法状态就会变成 s_req_http_HT,以此类推;
+若是空格,则认为是多余的空格,那么当前状态不做任何改变,并继续下一个扫描; - 但如果当前字符既不是空格也不是
H,那么好了,http-parser 直接认为你的请求包不合法,将你本次的解析设置错误 HPE_INVALID_CONSTANT并 goto到 error代码块。
至此,我们基本上已经明白了原因了:
http-parser 认为在 HTTP 请求包体中,第一行的 URI 解析阶段一旦出现了空格,就会认为 URI 解析完成,继而解析 HTTP 协议版本。但若此时紧跟着的不是 HTTP 协议版本的标准格式,http-parser 就会认为你这是一个 HPE_INVALID_CONSTANT的数据包。
不过,我们还是继续看看它的 error代码块吧:
error:
if (HTTP_PARSER_ERRNO(parser) == HPE_OK) {
SET_ERRNO(HPE_UNKNOWN);
}
RETURN(p - data);
这段代码中首先判断一下当跳到这段代码的时候有没有设置错误,若没有设置错误则将错误设置为未知错误(HPE_UNKNOWN),然后返回已解析的数据包长度。
p是当前解析字符指针,data是这个数据包的起始指针,所以 p - data就是已解析的数据长度。如果成功解析完,这个数据包理论上是等于这个数据包的完整长度,若不等则理论上说明肯定是中途出错提前返回。
回到 node_http_parser.cc
看完了 http-parser 的原理后,很多地方茅塞顿开。现在我们回到它的调用地 node_http_parser.cc继续阅读吧。
Local<Value> Execute(char* data, size_t len) {
...
size_t nparsed =
http_parser_execute(&parser_, &settings, data, len);
Local<Integer> nparsed_obj = Integer::New(env()->isolate(), nparsed);
if (!parser_.upgrade && nparsed != len) {
enum http_errno err = HTTP_PARSER_ERRNO(&parser_);
Local<Value> e = Exception::Error(env()->parse_error_string());
Local<Object> obj = e->ToObject(env()->isolate());
obj->Set(env()->bytes_parsed_string(), nparsed_obj);
obj->Set(env()->code_string(),
OneByteString(env()->isolate(), http_errno_name(err)));
return scope.Escape(e);
}
return scope.Escape(nparsed_obj);
}
从调用处我们能看见,在执行完 http_parser_execute()后有一个判断,若当前请求不是 upgrade请求(即请求头中有说明 Upgrade,通常用于 WebSocket),并且解析长度不等于原数据包长度(前文说了这种情况属于出错了)的话,那么进入中间的错误代码块。
在错误代码块中,先 HTTP_PARSER_ERRNO(&parser_)拿到错误码,然后通过 Exception::Error()生成错误对象,将错误信息塞进错误对象中,最后返回错误对象。
如果没错,则返回解析长度(nparsed_obj即 nparsed)。
在这个文件中,眼尖的童鞋可能发现了,执行 Execute()有好多处,这是因为实际上一个 HTTP 请求可能是流式的,所以有时候可能会只拿到部分数据包。所以最后有一个结束符需要被确认。这也是为什么 http-parser 在解析的时候只能逐字解析而不能跳跃或者后退了。
回到 _http_server.js
我们把 Parser::Execute()也就是 JavaScript 代码中的 parser.execute()给搞清楚后,我们就能回到 _http_server.js看代码了。
前文说了,socketOnData在解析完数据包后会执行 onParserExecuteCommon函数,现在就来看看这个 onParserExecuteCommon()函数。
function onParserExecuteCommon(server, socket, parser, state, ret, d) {
resetSocketTimeout(server, socket, state);
if (ret instanceof Error) {
debug('parse error', ret);
socketOnError.call(socket, ret);
} else if (parser.incoming && parser.incoming.upgrade) {
...
}
}
长长的一个函数被我精简成这么几句话,重点很明显。ret就是从 socketOnData传进来已解析的数据长度,但是在 C++ 代码中我们也看到了它还有可能是一个错误对象。所以在这个函数中一开始就做了一个判断,判断解析的结果是不是一个错误对象,如果是错误对象则调用 socketOnError()。
function socketOnError(e) {
// Ignore further errors
this.removeListener('error', socketOnError);
this.on('error', () => {});
if (!this.server.emit('clientError', e, this))
this.destroy(e);
}
我们看到,如果真的不小心走到这一步的话,HTTP Server 对象会触发一个 clientError事件。
整个事情串联起来了:
- 收到请求后会通过 http-parser 解析数据包;
GET /foo bar HTTP/1.1会被解析出错并返回一个错误对象;- 错误对象会进入
if (ret instanceof Error)条件分支并调用 socketOnError()函数; socketOnError()函数中会对服务器触发一个 clientError事件;(this.server.emit('clientError', e, this))- 至此,HTTP Server 并不会走到你的那个
function(req, resp)中去,所以不会有任何的数据被返回就结束了,也就解答了一开始的问题——收不到任何数据就请求结束。
这就是我要逐级进来看代码,而不是直达 http-parser 的原因了——clientError是一个关键。
处理办法
要解决这个“Bug”其实不难,直接监听 clientError事件并做一些处理即可。
'use strict';
const http = require('http');
const server = http.createServer(function(req, resp) {
console.log('');
resp.end('hello world');
}).on('clientError', function(err, sock) {
console.log('');
sock.end('HTTP/1.1 400 Bad Request\r\n\r\n');
});
server.listen(5555);
**注意:**由于运行到 clientError事件时,并没有任何 Request 和 Response 的封装,你能拿到的是一个 Node.js 中原始的 Socket 对象,所以当你要返回数据的时候需要自己按照 HTTP 返回数据包的格式来输出。
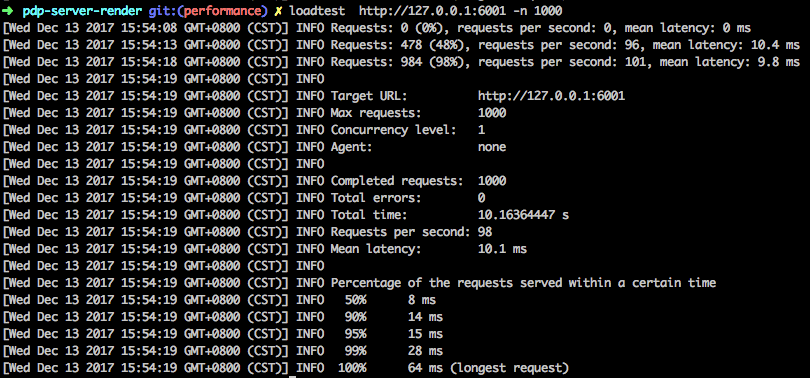
这个时候再挥起你的小手试一下 CURL 吧:
$ curl 'http://127.0.0.1:5555/d d' -v
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 5555 (#0)
> GET /d d HTTP/1.1
> Host: 127.0.0.1:5555
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 400 Bad Request
* no chunk, no close, no size. Assume close to signal end
<
* Closing connection 0
如愿以偿地输出了 400 状态码。
引申
接下来我们要引申讨论的一个点是,为什么这货不是一个真正意义上的 Bug。
首先我们看看 Nginx 这么实现这个黑科技的吧。
Nginx 实现
打开 Nginx 源码的相应位置。
我们能看到它的状态机对于 URI 和 HTTP 协议声明中间多了一个中间状态,叫 sw_check_uri_http_09,专门处理 URI 后面的空格。
在各种 URI 解析状态中,基本上都能找到这么一句话,表示若当前状态正则解析 URI 的各种状态并且遇到空格的话,则将状态改为 sw_check_uri_http_09。
case sw_check_uri:
switch (ch) {
case ' ':
r->uri_end = p;
state = sw_check_uri_http_09;
break;
...
}
...
然后在 sw_check_uri_http_09状态时会做一些检查:
case sw_check_uri_http_09:
switch (ch) {
case ' ':
break;
case CR:
r->http_minor = 9;
state = sw_almost_done;
break;
case LF:
r->http_minor = 9;
goto done;
case 'H':
r->http_protocol.data = p;
state = sw_http_H;
break;
default:
r->space_in_uri = 1;
state = sw_check_uri;
p--;
break;
}
break;
例如:
- 遇到空格则继续保持当前状态开始扫描下一位;
- 如果是换行符则设置默认 HTTP 版本并继续扫描;
- 如果遇到的是
H才修改状态为 sw_http_H认为接下去开始 HTTP 版本扫描; - 如果是其它字符,则标明一下 URI 中有空格,然后将状态改回
sw_check_uri,然后倒退回一格以 sw_check_uri继续扫描当前的空格。
在理解了这个“黑科技”后,我们很快能找到一个很好玩的点,开启你的 Nginx 并用 CURL 请求以下面的例子一下它看看吧:
$ curl 'http://xcoder.in:5555/d H' -v
* Trying 103.238.225.181...
* TCP_NODELAY set
* Connected to xcoder.in (103.238.225.181) port 5555 (#0)
> GET /d H HTTP/1.1
> Host: xcoder.in:5555
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 400 Bad Request
< Server: openresty/1.11.2.1
< Date: Tue, 12 Dec 2017 11:18:13 GMT
< Content-Type: text/html
< Content-Length: 179
< Connection: close
<
<html>
<head><title>400 Bad Request</title></head>
<body bgcolor="white">
<center><h1>400 Bad Request</h1></center>
<hr><center>openresty/1.11.2.1</center>
</body>
</html>
* Closing connection 0
怎么样?是不是发现结果跟之前的不一样了——它居然也返回了 400 Bad Request。
原因为何就交给童鞋们自己考虑吧。
RFC 2616 与 RFC 2396
那么,为什么即使在 Nginx 支持空格 URI 的情况下,我还说 Node.js 这个不算 Bug,并且指明 Nginx 是“黑科技”呢?
后来我去看了 HTTP 协议 RFC。
原因在于 Network Working Group 的 RFC 2616,关于 HTTP 协议的规范。
在 RFC 2616 的 3.2.1 节中做了一些说明,它说了在 HTTP 协议中关于 URI 的文法和语义参照了 RFC 2396。
URIs in HTTP can be represented in absolute form or relative to some known base URI, depending upon the context of their use. The two forms are differentiated by the fact that absolute URIs always begin with a scheme name followed by a colon. For definitive information on URL syntax and semantics, see “Uniform Resource Identifiers (URI): Generic Syntax and Semantics,” RFC 2396 (which replaces RFCs 1738 and RFC 1808). This specification adopts the definitions of “URI-reference”, “absoluteURI”, “relativeURI”, “port”, “host”,“abs_path”, “rel_path”, and “authority” from that specification.
而在 RFC 2396中,我们同样找到了它的 2.4.3 节。里面对于 Disallow 的 US-ASCII 字符做了解释,其中有:
控制符,指 ASCII 码在 0x00-0x1F 范围内以及 0x7F;
控制符通常不可见;
空格,指 0x20;
空格不可控,如经由一些排版软件转录后可能会有变化,<span style=“color: #ccc;”>而到了 HTTP 协议这层时,反正空格不推荐使用了,所以就索性用空格作为首行分隔符了;</span>
分隔符,"<"、">"、"#"、"%"、"\""。
如 #将用于浏览器地址栏的 Hash;而 %则会与 URI 转义一同使用,所以不应单独出现在 URI 中。
于是乎,HTTP 请求中,包体的 URI 似乎本就不应该出现空格,而 Nginx 是一个黑魔法的姿势。
小结
嚯,写得累死了。本次的一个探索基于了一个有空格非正常的 URI 通过 CURL 或者其它一些客户端请求时,Node.js 出现的 Bug 状态。
实际上发现这个 Bug 的时候,客户端请求似乎是因为那边的开发者手抖,不小心将不应该拼接进来的内容给拼接到了 URL 中,类似于 $ rm -rf /。
一开始我以为这是 Node.js 的 Bug,在探寻之后发现是因为我们自己没用 Node.js HTTP Server 提供的 clientError事件做正确的处理。而 Nginx 的正常请求则是它的黑科技。这些答案都能从 RFC 中寻找——再次体现了遇到问题看源码看规范的重要性。
另,我本打算给 http-parser 也加上黑魔法,后来我快写好的时候发现它是流式的,很多状态没法在现有的体系中保留下来,最后放弃了,反正这也不算 Bug。不过在以后有时间的时候,感觉还是可以好好整理一下代码,好好修改一下给提个 PR 上去,以此自勉。
最后,求 fafa。
![求 fafa]()
交流
如果你有更多的想法,或者想了解蚂蚁金服的 Node.js、前端以及设计小伙伴们的更多姿势,可以报名首届蚂蚁体验科技大会 SEE Conf,比如有死马大大的《Developer Experience First —— Techless Web Application 的理念与实践》,还有青栀大大的《蚂蚁开发者工具,服务蚂蚁生态的移动研发 IDE》等等。
报名官网:https://seeconf.alipay.com/
期待您的光临。